

Dear researchers,
My name is Ui Young Sun, a third-year doctoral student studying OB/HR at the University of Illinois at Chicago. I and my research team are working on the project that investigates people’s reaction to different stigmatized identity groups. Currently, we plan to present three different identity groups to participants, which are randomly selected from the list of 20 identity groups. These identity groups need to be incorporated into texts and items. (for example, “I have seen an identity group 1 (or 2, etc.) in a movie.” This survey will have a time-lagged design (three time-points, a 2-week interval).
We are struggling with how to appropriately set up the Qualtrics survey. First, we need to randomly present 3 groups out of 20. And then we need to maintain the chosen 3 groups and incorporate them into the texts and questions for each participant throughout the surveys at different time points. If we use just a randomizer function in the survey flow and then we need to make so many different versions of the survey. Also, currently, I do not have a good idea about how I can maintain the chosen identities for each participant. It would be very grateful if you, the experts in Qualtrics, provide some helpful tips or guidance to deal with these issues.
I give my thanks in advance.
Best regards,
Ui Young Sun
Best answer by TomG
View original

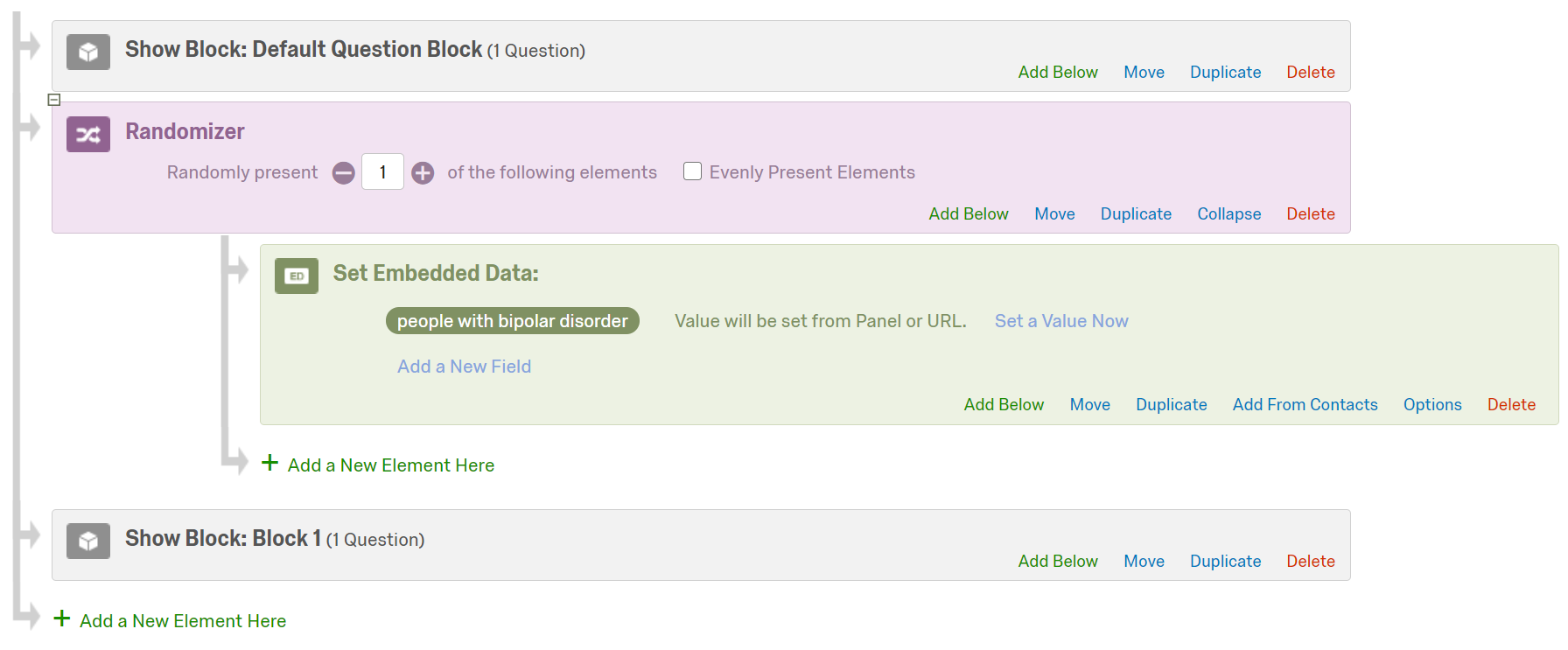 Second, from your explanations, it seems that I need the 2nd and 3rd randomizers and use branches so that I may not assign duplicate groups. I was not quite sure about where I should make randomizers. Should I make randomizers at an equal level? How specifically shall I use branch function to avoid potential duplication? Finally, I tried to pipe in the text from the embedded field. But, in the embedded field, there are to be many groups (e.g., group1, group 2, etc.) So, I am not sure about how I make them to be randomly assigned and then consistently appear throughout the surveys at different time points.
Second, from your explanations, it seems that I need the 2nd and 3rd randomizers and use branches so that I may not assign duplicate groups. I was not quite sure about where I should make randomizers. Should I make randomizers at an equal level? How specifically shall I use branch function to avoid potential duplication? Finally, I tried to pipe in the text from the embedded field. But, in the embedded field, there are to be many groups (e.g., group1, group 2, etc.) So, I am not sure about how I make them to be randomly assigned and then consistently appear throughout the surveys at different time points.