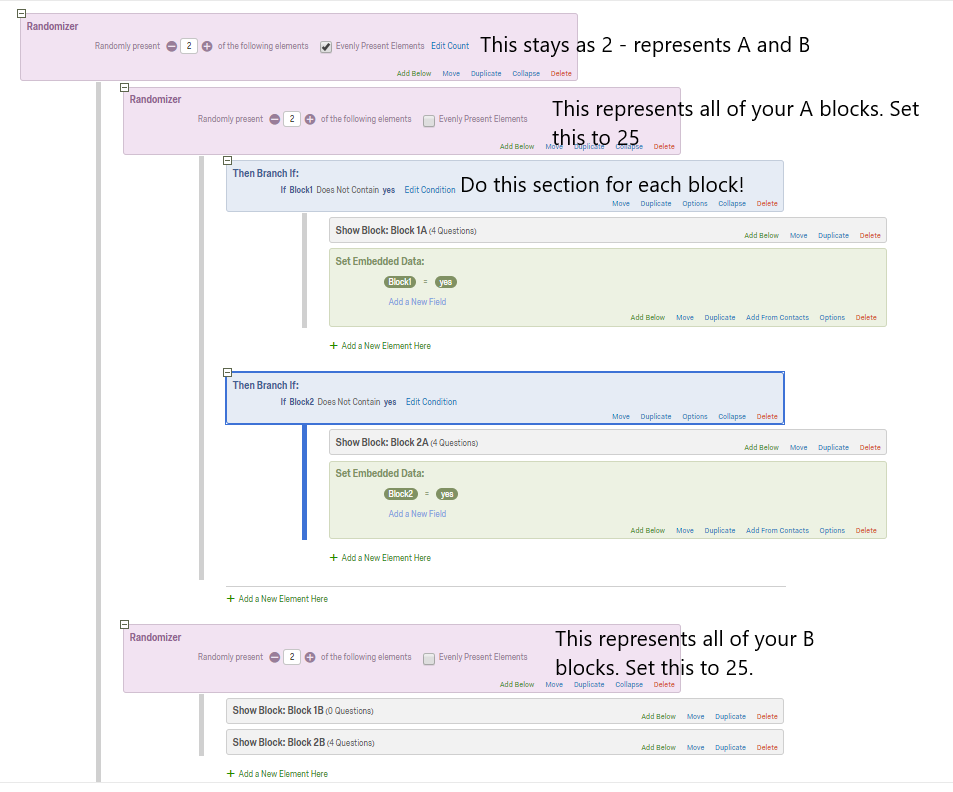
") . It means I have 200 blocks in total, i.e. block 1A, block 1B, block 2A, block 2B, ….
. It means I have 200 blocks in total, i.e. block 1A, block 1B, block 2A, block 2B, ….Now I want to randomly show them 50 blocks including 25 blocks of version A and 25 blocks of version B, given that if a block is shown with version A, it will not be shown with version B.
If I put all of 200 blocks under a Randomizer in Survey Flow, and randomly choose 50 out of 200, it will lead to 2 problems:
- Problem 1: I may get 40 blocks of version A and 10 blocks of version B instead of 25 version A blocks and 25 version B blocks.
- Problem 2: one block may be shown with both version A and B.
Could you advise me how to use Qualtrics features to overcome 2 problem, especially problem 2?
Thank you very much.
Tomas