I am trying to test whether participants are correctly judging two sentences belonging to a sentence pair on comparative difficulty. I'm using two slider-type questions with values ranging from 1 to 100 where 1 has the label ‘Very easy’ and 2 has the label ‘Very hard’. The sentence pairs are presented directly underneath one another on the same page.
In order to make sure that participants understand what they have to do, I have five practice sentences with obviously complicated sentences and an obviously less complicated sentence to match it. I want to make sure that the complicated sentences are indeed judged as being more complicated than the uncomplicated sentences for the majority of the practice block, so that participants can be excluded (and therefore re-directed back to Prolific in order to return their submission) if they consistently make errors.
My questions are therefore as follows:
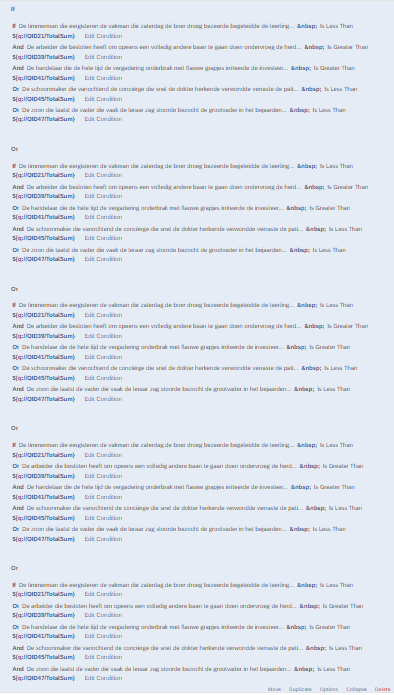
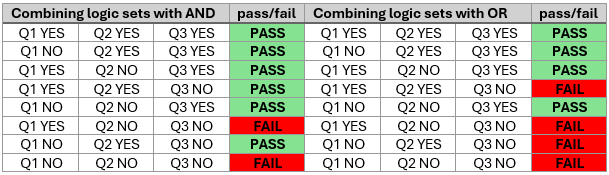
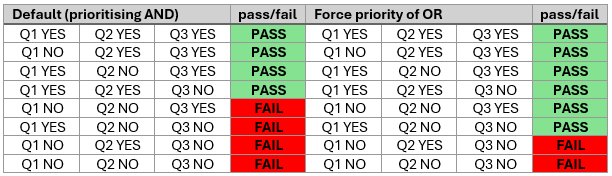
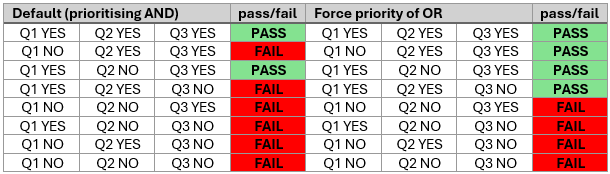
- How would you have the branching structure compare the answer of a question to the value in a different question that's presented at the same time?
- Is it even possible to have Qualtrics count the number of times the above condition is met over 5 different questions (i.e., paired sentence ratings), so that I can exclude participants only if they get X out of 5 incorrect? (And if this is possible, how would I do it?)