
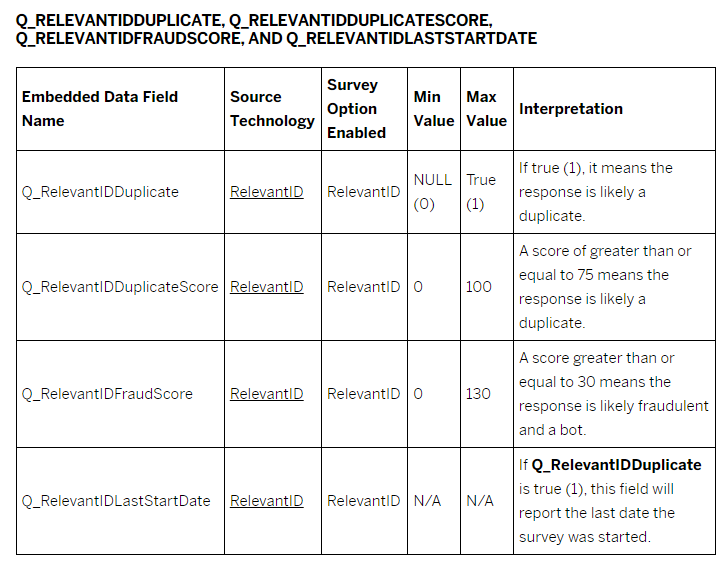
I am conducting a survey with 2,000 individuals and have noticed a significant number of high RelevantID Fraud Scores (score of 30 or higher). I am seeking clarification on what this indicator represents and how it should be interpreted. Additionally, there are other indicators such as Q_RelevantIDDuplicate, Q_RecaptchaScore, and Q_BallotBoxStuffing, which capture different types of fraud activities. How do these differ from the RelevantID Fraud Score? This issue is particularly puzzling because when I cross-validate the data without excluding respondents with a RelevantID score of 30 or higher, my dataset aligns more closely with the national sample compared to when I exclude these respondents.

Question
How to Interpret the RelevantID Fraud Score?

Sign up
Already have an account? Login

Welcome! To join the Qualtrics Experience Community, log in with your existing Qualtrics credentials below.
Confirm your username, share a bit about yourself, then you're ready to explore and connect .
Free trial account? No problem. Log in with your trial credentials to join.
No free trial account? No problem! Register here
Already a member? Hi and welcome back! We're glad you're here 🙂
You will see the Qualtrics login page briefly before being taken to the Experience Community.
Login with Qualtrics
Welcome! To join the Qualtrics Experience Community, log in with your existing Qualtrics credentials below.
Confirm your username, share a bit about yourself, then you're ready to explore and connect .
Free trial account? No problem. Log in with your trial credentials to join. No free trial account? No problem! Register here
Already a member? Hi and welcome back! We're glad you're here 🙂
You will see the Qualtrics login page briefly before being taken to the Experience Community.
Login to the Community
No account yet? Create an account
Welcome! To join the Qualtrics Experience Community, log in with your existing Qualtrics credentials below.
Confirm your username, share a bit about yourself, then you're ready to explore and connect .
Free trial account? No problem. Log in with your trial credentials to join.
No free trial account? No problem! Register here
Already a member? Hi and welcome back! We're glad you're here 🙂
You will see the Qualtrics login page briefly before being taken to the Experience Community.
Login with Qualtrics
Welcome! To join the Qualtrics Experience Community, log in with your existing Qualtrics credentials below.
Confirm your username, share a bit about yourself, then you're ready to explore and connect .
Free trial account? No problem. Log in with your trial credentials to join. No free trial account? No problem! Register here
Already a member? Hi and welcome back! We're glad you're here 🙂
You will see the Qualtrics login page briefly before being taken to the Experience Community.
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.