I’m wondering if there is a way to randomize questions in a block, but constrain the randomization such that certain questions don’t appear after specific other questions.
For example, imagine we have questions [Q1...Q10]. I’d like to randomize them such that Q2 doesn’t appear adjacent to (immediately before or after) Q6, Q3 doesn’t appear adjacent to Q8 etc. I don’t want to skip these questions entirely; just have them appear in different places such that they aren’t next to the other questions.
Alternatively, is there any way to import a csv file with a randomization list that might determine the order in which questions appear? If I generated a csv or txt file which had a list of 50 permissible question orders (e.g., lists that looked like [Q3,Q2,Q5,Q1,Q6,Q8,Q9,Q4]), would I then be able to use that csv file to tell qualtrics which order questions within a block should be shown?
I’m open to other ways to do this. Thanks in advance!
Best answer by omkarkewat
@mmukherji sorry for late reply!
NOTE: It will be a lengthy set up.
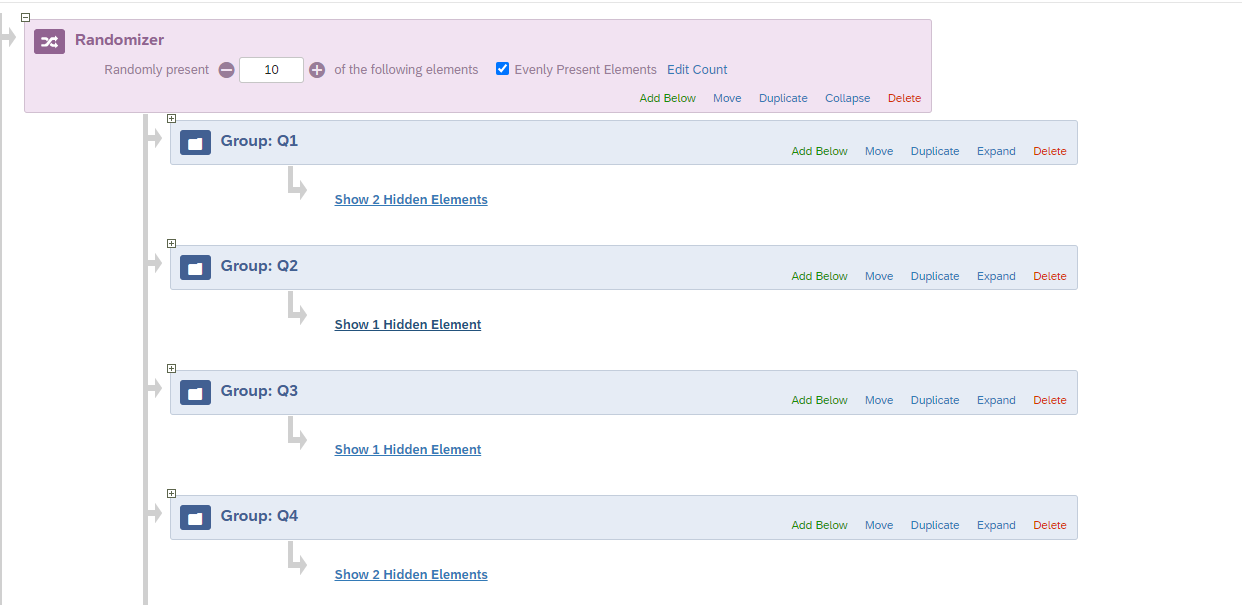
STEP 1: Create 10 blocks for 10 questions which will have a single question in a single block.
STEP 2: In the survey flow, create a randomizer which will contain all the 10 blocks in it. Keep the randomizer value as 10 and tick the check box for ‘Evenly present elements’.
Each group will contain a block of question with some embedded data.
STEP 3:
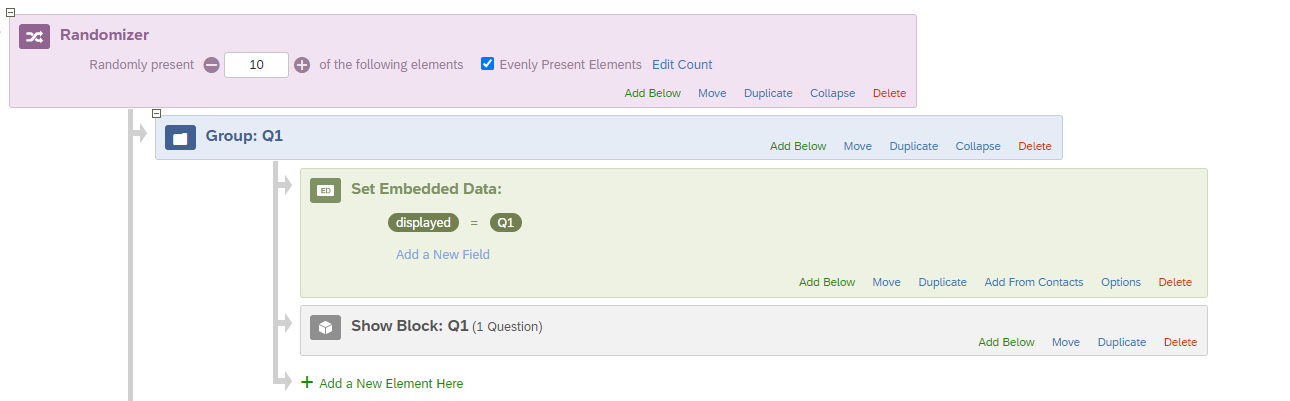
Inside each group create an embedded data which will act as a flag for that particular block.
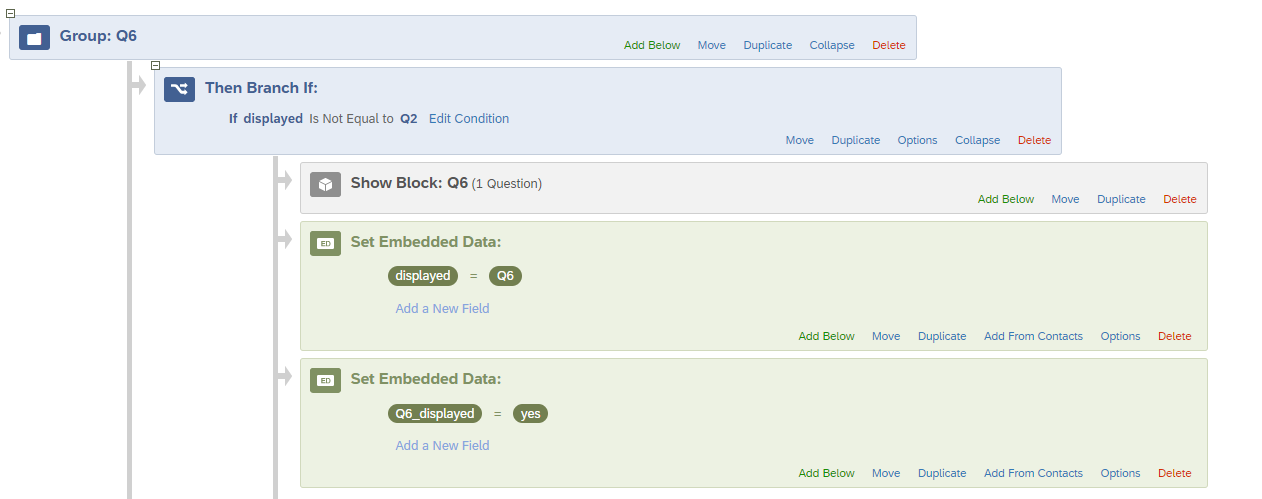
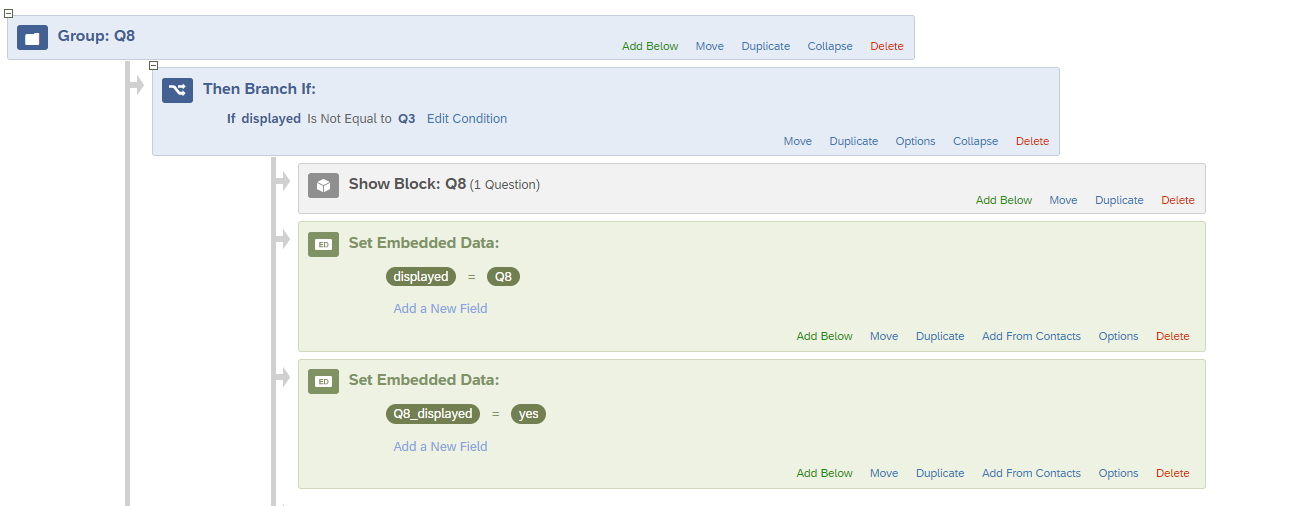
STEP 4: This step is particularly for Q2, Q3. Q6 and Q8.
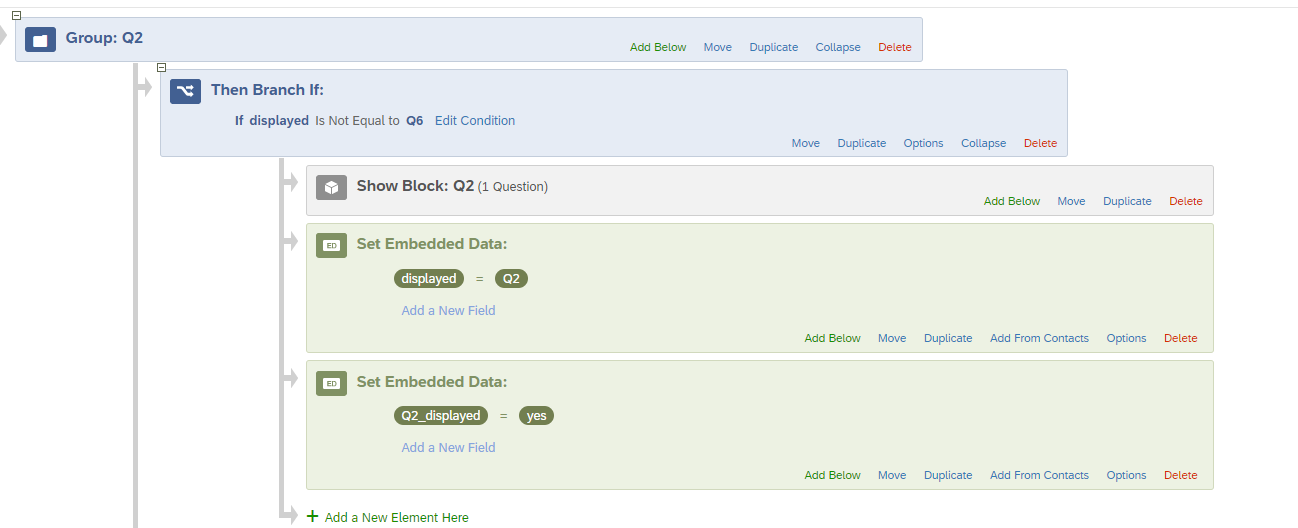
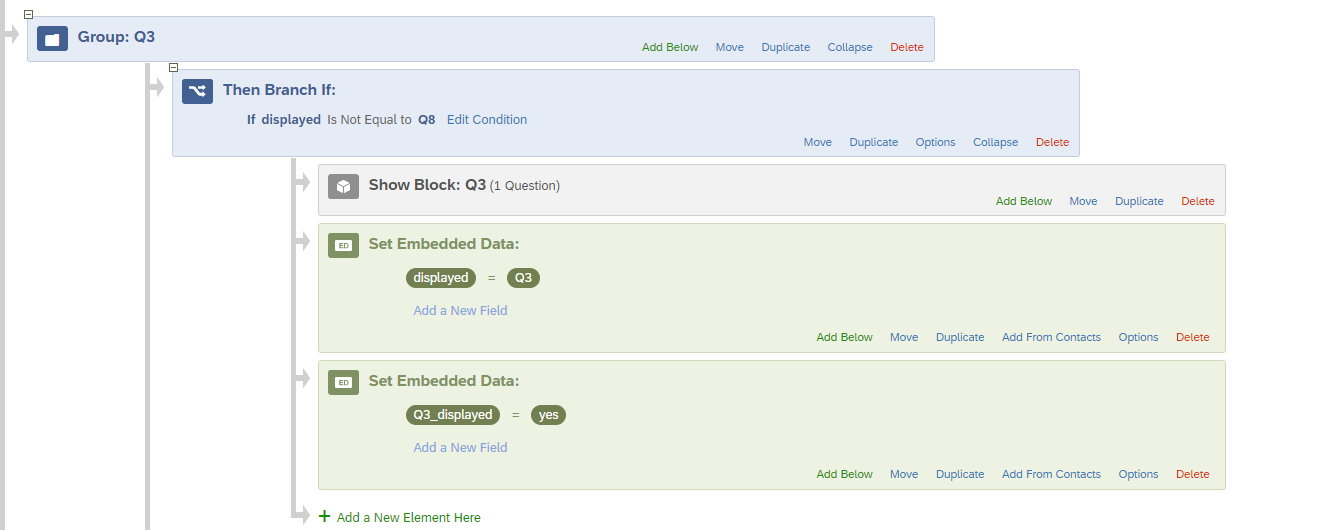
Block Q2 will only be displayed if embedded data ‘displayed’ is not equal to Q6, this will prevent Q2 from showing just after Q6.(Please ignore the embedded data ‘Q2_displayed’, it will be explained in the further steps.) Repeat this similar process for block Q3, Q6 and Q8 as well. Refer below images.
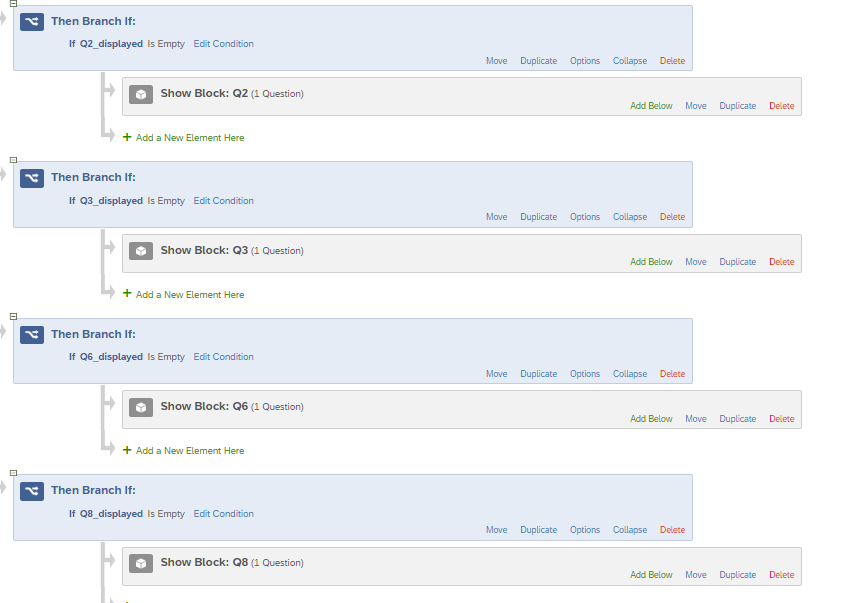
STEP 5: Let’s say if group Q2 gets selected by the randomizer just after group Q6. In this case the Q2 will not be displayed as it has a branch condition saying display only if ”embedded data ‘displayed’ is not equal to Q6”. So to manage this condition we will add more branch logics at the end of this randomizer setup and the embedded that I asked you to ignore in the earlier step will come into picture.
The respective block will be displayed at the end if it wasn’t displayed earlier using the new embedded data condition.
END!
VERY IMP NOTE: Please perform multiple rounds of testing as there might be some loop holes (like the ‘STEP 5’. Even I came to know about it when I tested the setup but didn’t get time to perform more rounds of testing) that were not covered in the above setup. And if you find any, we can customize the setup again!
Hi @mmukherji you can try this setup in the survey flow using branch logics, embedded data and randomizer element; if you have each question in a separate block.
@omkarkewat thanks for the suggestion! What branch logics/embedded data should I be looking into? If I had Q2 and Q6 in different blocks under my randomizer and didn’t want them to appear adjacent to each other, how would I implement it using branch logics and embedded data?
STEP 1: Create 10 blocks for 10 questions which will have a single question in a single block.
STEP 2: In the survey flow, create a randomizer which will contain all the 10 blocks in it. Keep the randomizer value as 10 and tick the check box for ‘Evenly present elements’.
Each group will contain a block of question with some embedded data.
STEP 3:
Inside each group create an embedded data which will act as a flag for that particular block.
STEP 4: This step is particularly for Q2, Q3. Q6 and Q8.
Block Q2 will only be displayed if embedded data ‘displayed’ is not equal to Q6, this will prevent Q2 from showing just after Q6.(Please ignore the embedded data ‘Q2_displayed’, it will be explained in the further steps.) Repeat this similar process for block Q3, Q6 and Q8 as well. Refer below images.
STEP 5: Let’s say if group Q2 gets selected by the randomizer just after group Q6. In this case the Q2 will not be displayed as it has a branch condition saying display only if ”embedded data ‘displayed’ is not equal to Q6”. So to manage this condition we will add more branch logics at the end of this randomizer setup and the embedded that I asked you to ignore in the earlier step will come into picture.
The respective block will be displayed at the end if it wasn’t displayed earlier using the new embedded data condition.
END!
VERY IMP NOTE: Please perform multiple rounds of testing as there might be some loop holes (like the ‘STEP 5’. Even I came to know about it when I tested the setup but didn’t get time to perform more rounds of testing) that were not covered in the above setup. And if you find any, we can customize the setup again!
@omkarkewat thanks a lot, I really appreciate the help! Slight issue with step 5: if we didn’t want Q2 after Q6, then adding the branching logic would make Q2 appear after Q6.
This could work, maybe with lots and lots more branching (which sounds tedious), but I wish there was a way to read from a csv that listed all the possible questions… seems like a straightforward way to set up randomization, but from what I’ve seen, qualtrics doesn’t seem to have a straightforward way to allow this.