Hello Everyone,
I am writing here because I am encountering some issues when creating my survey for my thesis. I am studying whether matching a chatbot personality to the user can yield to a greater acceptance.
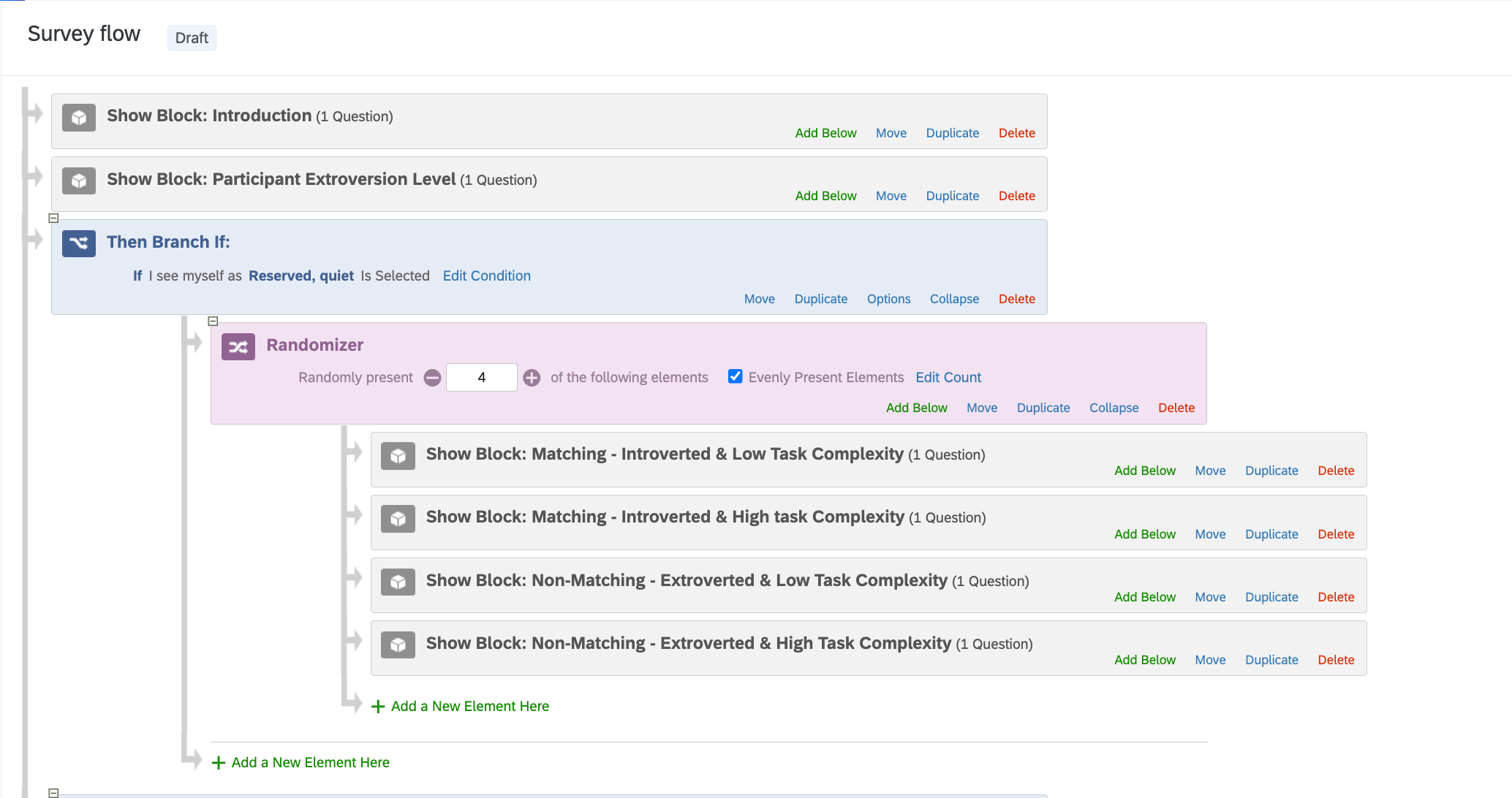
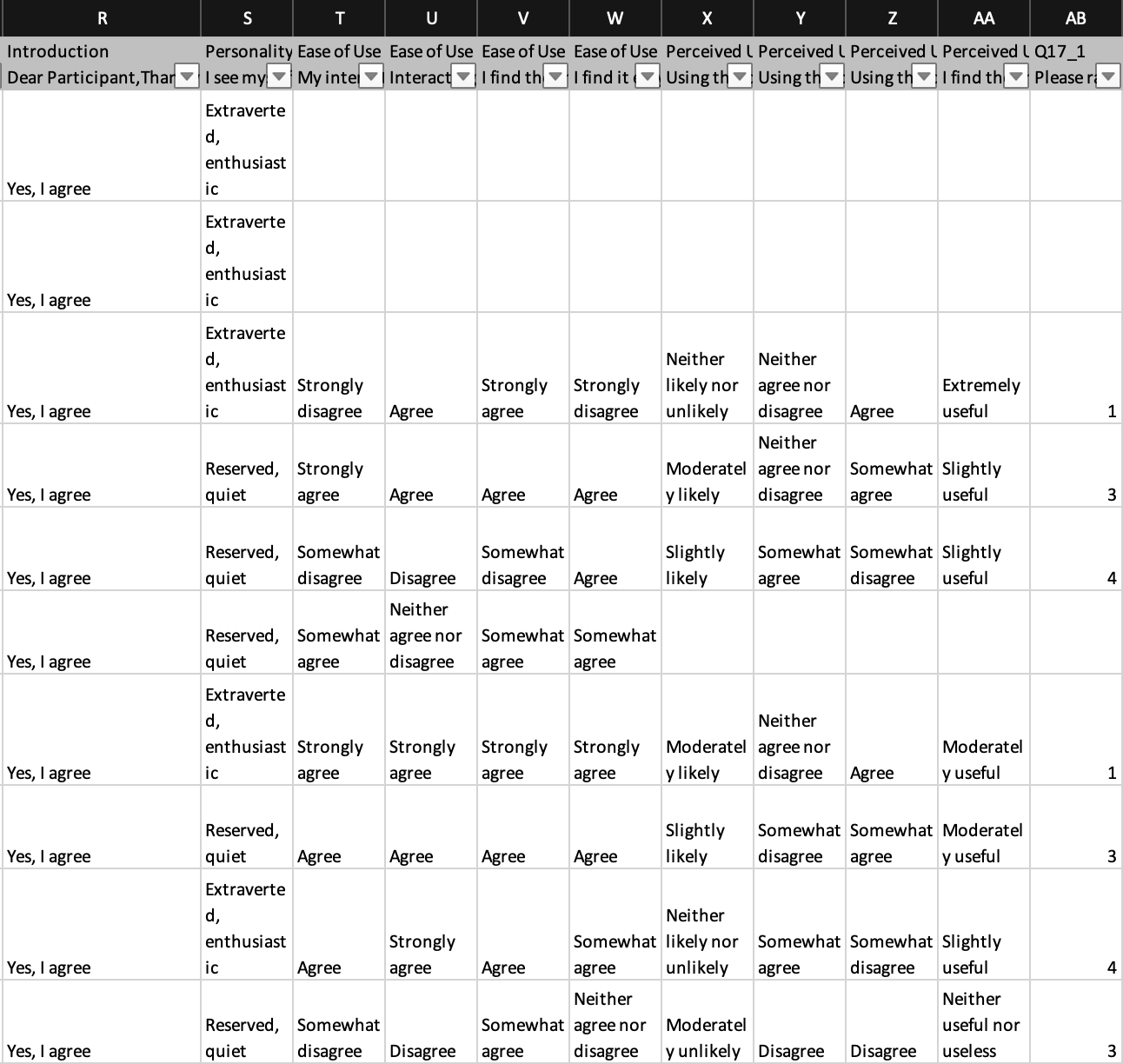
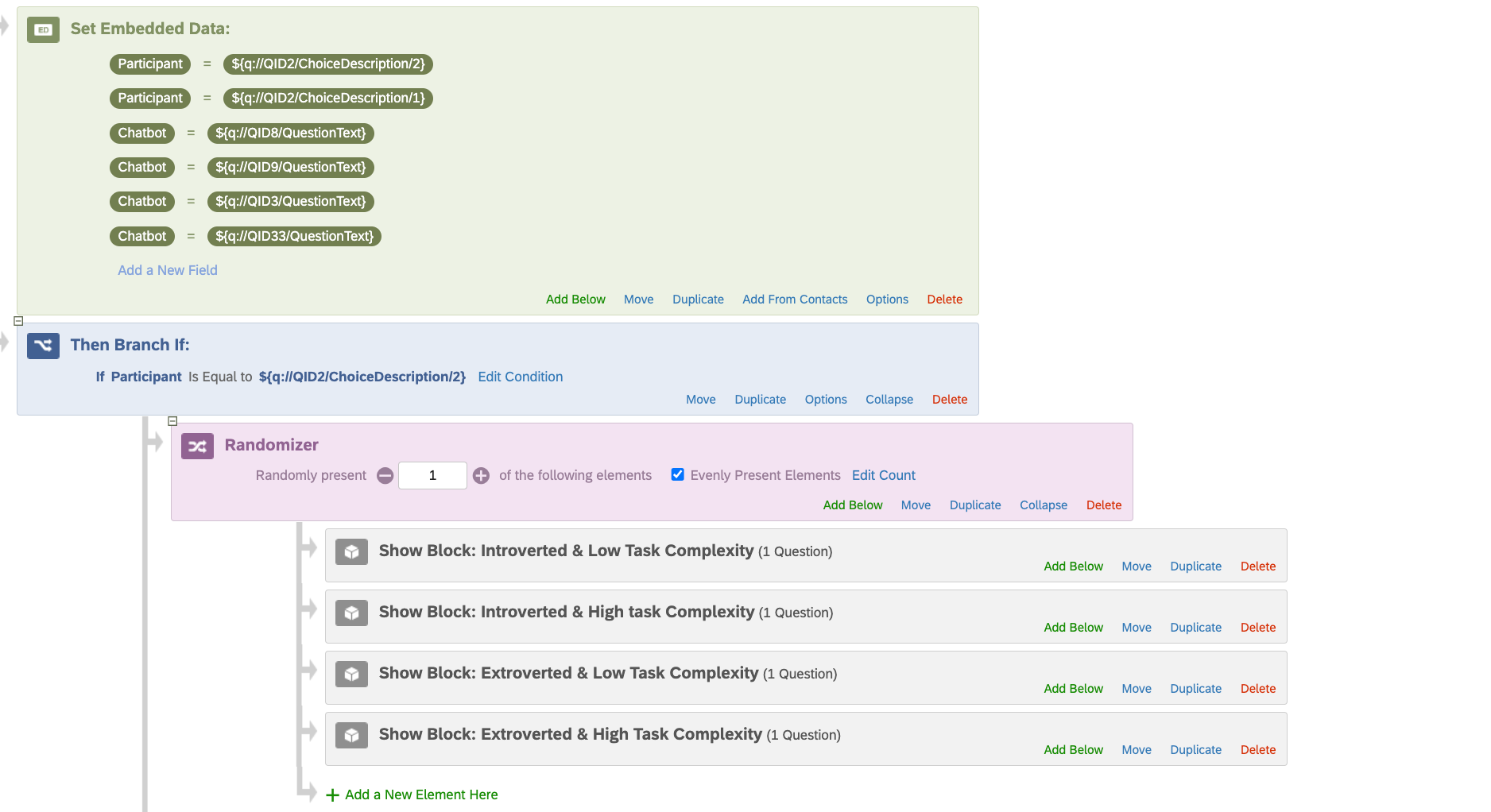
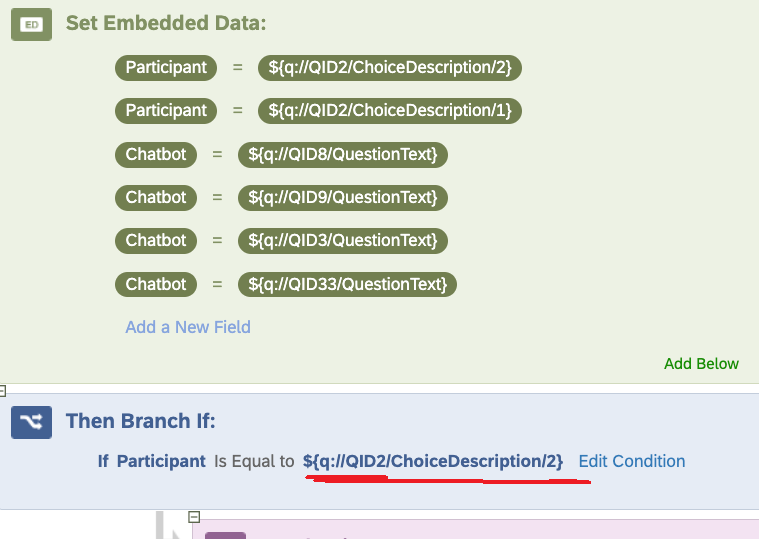
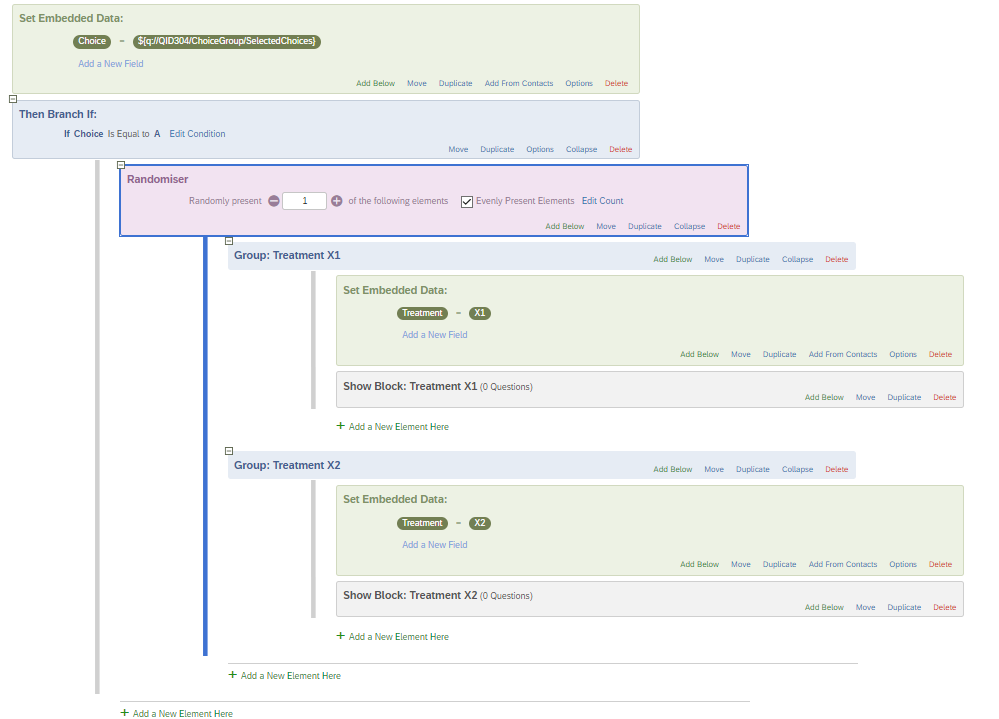
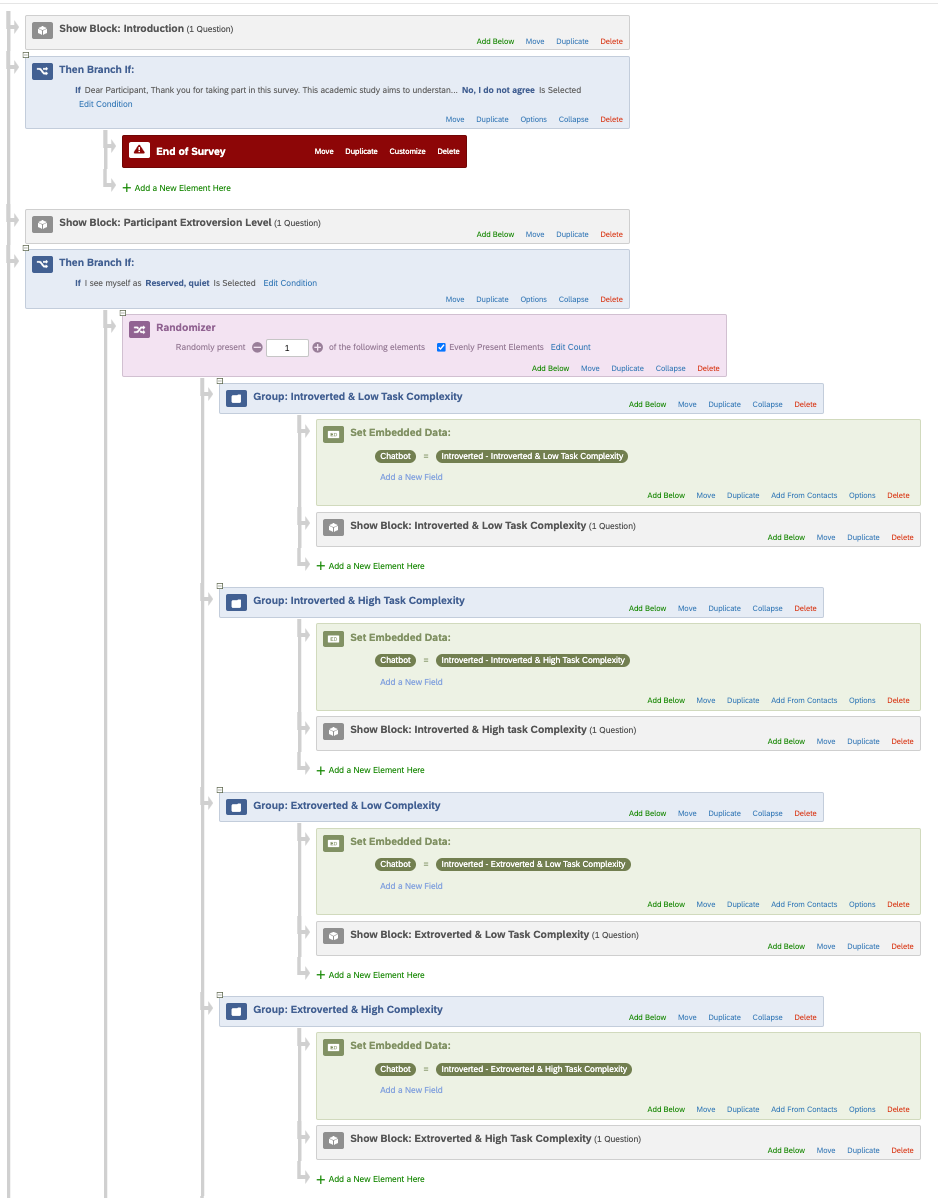
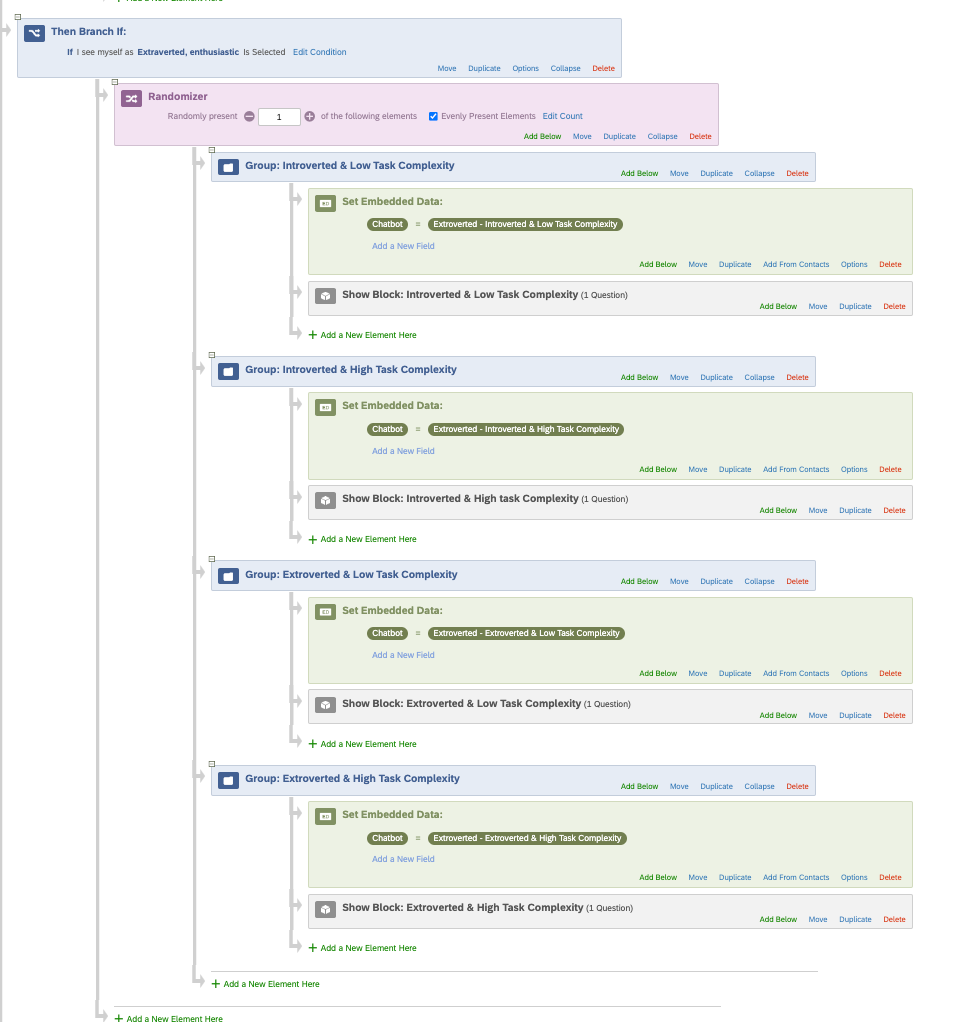
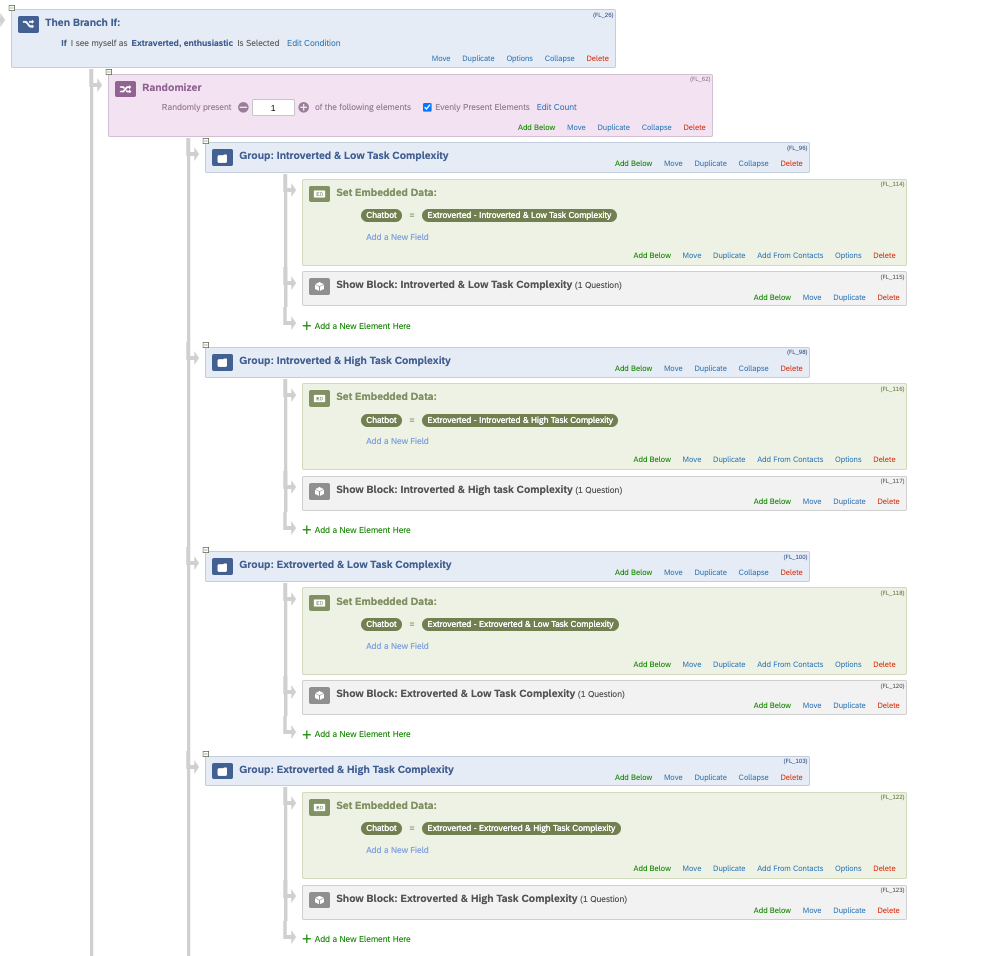
To do so, after asking their personality type, I would like to assign each participant randomly to different treatments. However, with the way I’m doing things, the participant goes through all these blocks one after the other. Here below is a screenshot of the Survey Flow.
Is there a way to go in which the participant selects an answer from a questions and is allocated randomly to one of these following blocks once?
Your assistance upon this matter is highly appreciated.
Best regards,
Jorge Ibanez