
I am working on my survey which includes 2 recipes, and each recipe has 7 different experimental conditions. Participants are randomly placed in one of the 7 conditions for the first recipe. For the 2dn recipe, they should be placed in the same condition as for the first recipe. How do I do that?
so: participant is placed randomly in condition 2 for recipe 1 and should be placed in condition 2 for recipe 2
Any help would be appreciated!

Solved
Specific survey flow question
Best answer by wpm24
It sounds like what you want to do can be done with a randomizer (which you already have) and embedded data. Embedded data, allows you to attach a data point to a participant and then recall that data point to use later. Only participants that are exposed to the data point will have it attached to them. Thus, by creating a unique embedded data point for each condition in recipe 1, we can recall that unique data point to show participants the correct recipe 2.
Step 1. Create all recipe 1 blocks.
Step 2. In survey flow, add a randomizer.
Step 3. Use the 'group' element create a group for each condition under the randomizer (see image below). 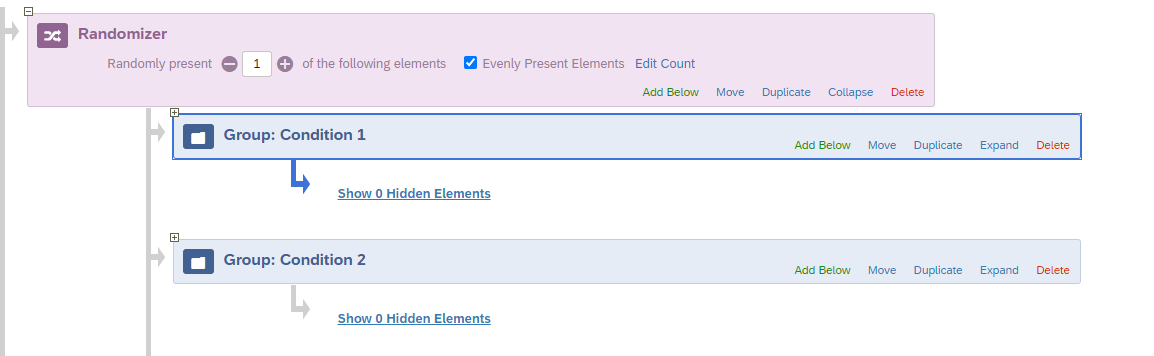 Step 4. Use the embedded data element to create an embedded condition variable under each group.
Step 4. Use the embedded data element to create an embedded condition variable under each group.
Step 5. Add the relative block of questions for that condition under its respective group. (see image below for steps 4 and 5). 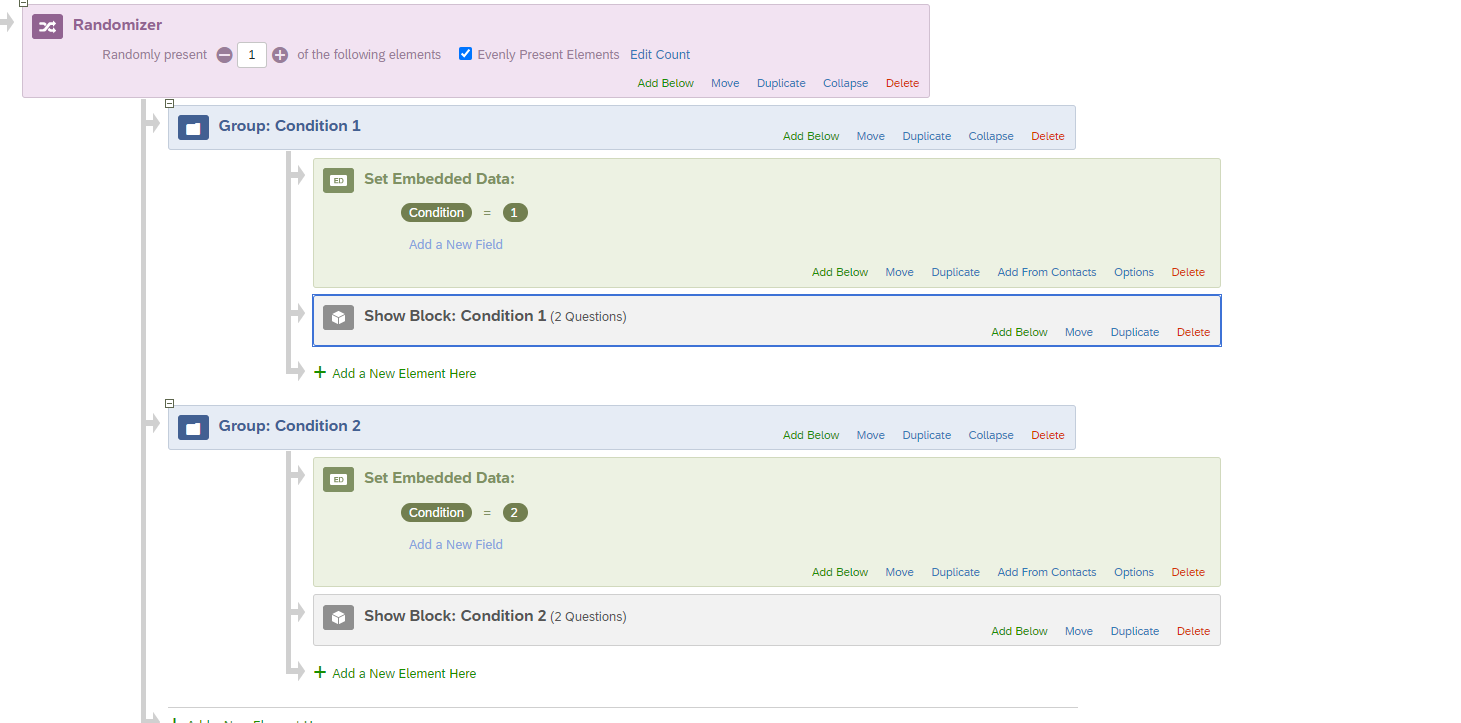 Step 6. Now create a branch logic and set the parameters to be 'If Condition is equal to X, then...." where X is the condition number (1, 2, 3, 4...) and for the 'then' place the recipe 2 version of the block. If I understand correctly, you should have 7 embedded data points and 7 branching logics (1 for each condition). Very important, you have to make sure that how you type your embedded data variables both the label (e.g., 'Condition') and values (e.g., 1) are the exact same in the branching logic. This is case sensitive. See image below. *I made an error in my block label one block should say "Condition 1pt2" to symbolize the second recipe.
Step 6. Now create a branch logic and set the parameters to be 'If Condition is equal to X, then...." where X is the condition number (1, 2, 3, 4...) and for the 'then' place the recipe 2 version of the block. If I understand correctly, you should have 7 embedded data points and 7 branching logics (1 for each condition). Very important, you have to make sure that how you type your embedded data variables both the label (e.g., 'Condition') and values (e.g., 1) are the exact same in the branching logic. This is case sensitive. See image below. *I made an error in my block label one block should say "Condition 1pt2" to symbolize the second recipe. 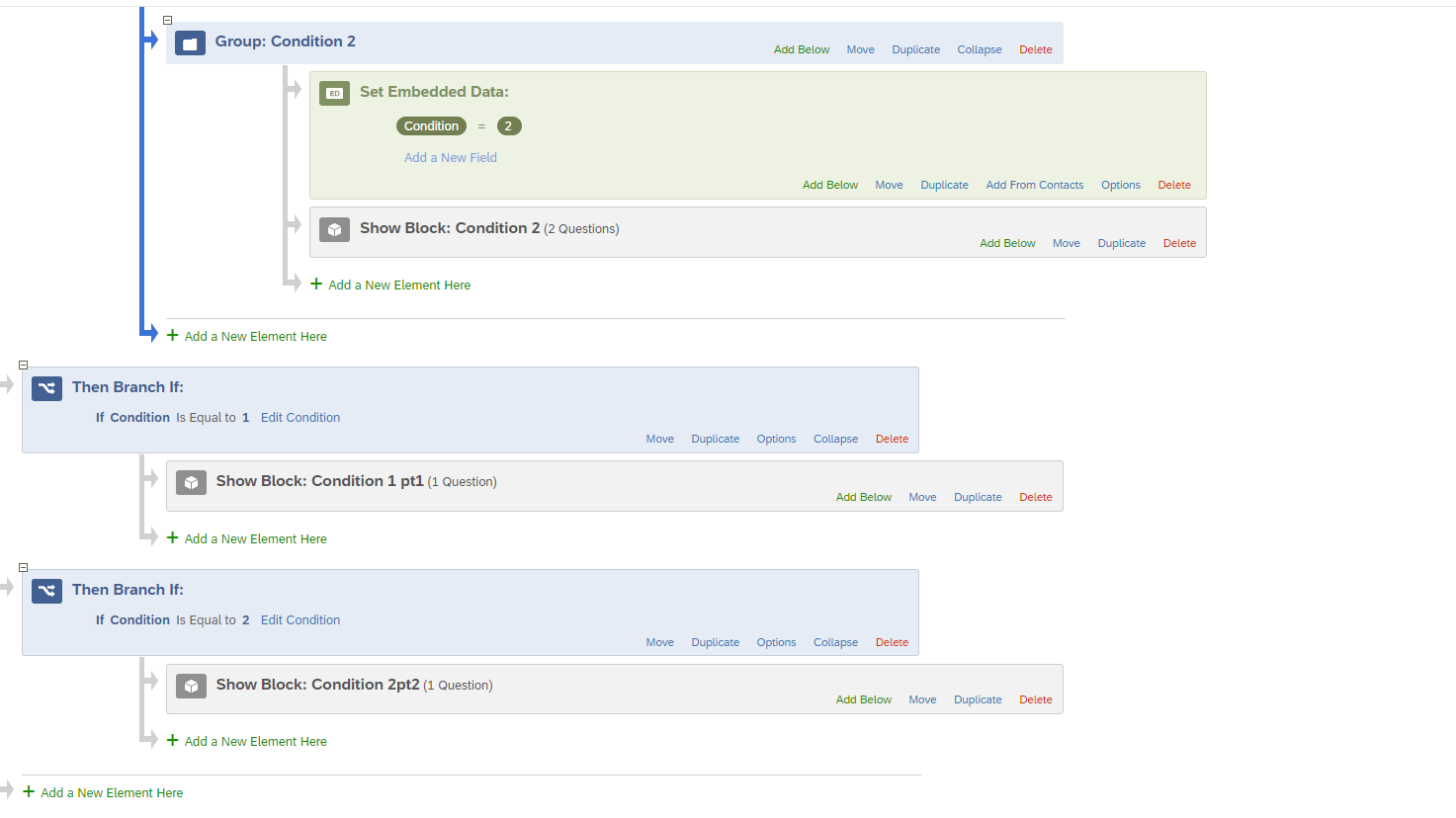
Hope this helps!

Sign up
Already have an account? Login

Welcome! To join the Qualtrics Experience Community, log in with your existing Qualtrics credentials below.
Confirm your username, share a bit about yourself, then you're ready to explore and connect .
Free trial account? No problem. Log in with your trial credentials to join.
No free trial account? No problem! Register here
Already a member? Hi and welcome back! We're glad you're here 🙂
You will see the Qualtrics login page briefly before being taken to the Experience Community.
Login with Qualtrics
Welcome! To join the Qualtrics Experience Community, log in with your existing Qualtrics credentials below.
Confirm your username, share a bit about yourself, then you're ready to explore and connect .
Free trial account? No problem. Log in with your trial credentials to join. No free trial account? No problem! Register here
Already a member? Hi and welcome back! We're glad you're here 🙂
You will see the Qualtrics login page briefly before being taken to the Experience Community.
Login to the Community
No account yet? Create an account
Welcome! To join the Qualtrics Experience Community, log in with your existing Qualtrics credentials below.
Confirm your username, share a bit about yourself, then you're ready to explore and connect .
Free trial account? No problem. Log in with your trial credentials to join.
No free trial account? No problem! Register here
Already a member? Hi and welcome back! We're glad you're here 🙂
You will see the Qualtrics login page briefly before being taken to the Experience Community.
Login with Qualtrics
Welcome! To join the Qualtrics Experience Community, log in with your existing Qualtrics credentials below.
Confirm your username, share a bit about yourself, then you're ready to explore and connect .
Free trial account? No problem. Log in with your trial credentials to join. No free trial account? No problem! Register here
Already a member? Hi and welcome back! We're glad you're here 🙂
You will see the Qualtrics login page briefly before being taken to the Experience Community.
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.