
Hi All,
Just testing out the data privacy request process where it prepares a compressed .gz file that you have to download, then extract (using 7zip) and then you get the json file.
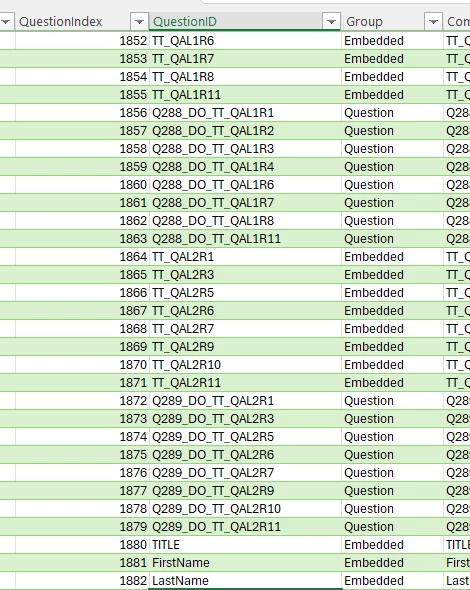
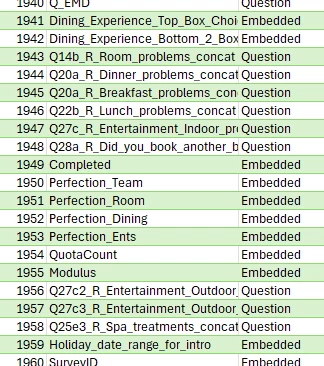
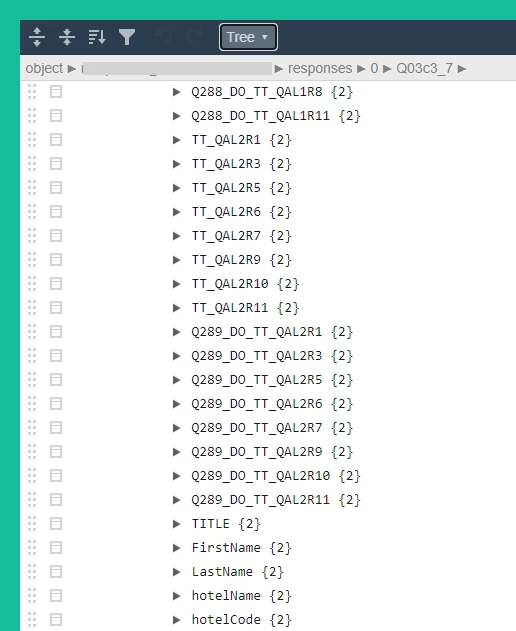
The problem is what to do with the JSON file as it's a specific structure / schema that I can't work out. Can anyone help?
I've got as far as trying to use Power Query in excel to convert it but I'm stuck at the point of drilling down / expanding the records into tables. The responses are for one person but across multiple surveys and so merging them into one columns won't work.
To be honest I'm not that interested in the response but I'm more interested in just seeing at top level what surveys the person was found in but I guess it's all or nothing.
Hope someone can help on this. Really surprised that on this page - https://www.qualtrics.com/support/survey-platform/sp-administration/data-privacy-tab/right-to-erasure/#Download
Qualtrics tell you that it'll be a JSON file and then leave you to it! There is no help in how you interpret the data file!!
Hope someone can help
Thanks
Rod Pestell

help to interpret JSON data privacy download (.gz / JSON ) file

Sign up
Already have an account? Login

Welcome! To join the Qualtrics Experience Community, log in with your existing Qualtrics credentials below.
Confirm your username, share a bit about yourself, then you're ready to explore and connect .
Free trial account? No problem. Log in with your trial credentials to join.
No free trial account? No problem! Register here
Already a member? Hi and welcome back! We're glad you're here 🙂
You will see the Qualtrics login page briefly before being taken to the Experience Community.
Login with Qualtrics
Welcome! To join the Qualtrics Experience Community, log in with your existing Qualtrics credentials below.
Confirm your username, share a bit about yourself, then you're ready to explore and connect .
Free trial account? No problem. Log in with your trial credentials to join. No free trial account? No problem! Register here
Already a member? Hi and welcome back! We're glad you're here 🙂
You will see the Qualtrics login page briefly before being taken to the Experience Community.
Login to the Community
No account yet? Create an account
Welcome! To join the Qualtrics Experience Community, log in with your existing Qualtrics credentials below.
Confirm your username, share a bit about yourself, then you're ready to explore and connect .
Free trial account? No problem. Log in with your trial credentials to join.
No free trial account? No problem! Register here
Already a member? Hi and welcome back! We're glad you're here 🙂
You will see the Qualtrics login page briefly before being taken to the Experience Community.
Login with Qualtrics
Welcome! To join the Qualtrics Experience Community, log in with your existing Qualtrics credentials below.
Confirm your username, share a bit about yourself, then you're ready to explore and connect .
Free trial account? No problem. Log in with your trial credentials to join. No free trial account? No problem! Register here
Already a member? Hi and welcome back! We're glad you're here 🙂
You will see the Qualtrics login page briefly before being taken to the Experience Community.
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.