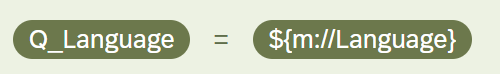Hi everyone! I’m hoping you all can help with an issue we’re encountering regarding embedded data fields, branching, and a question randomizer.
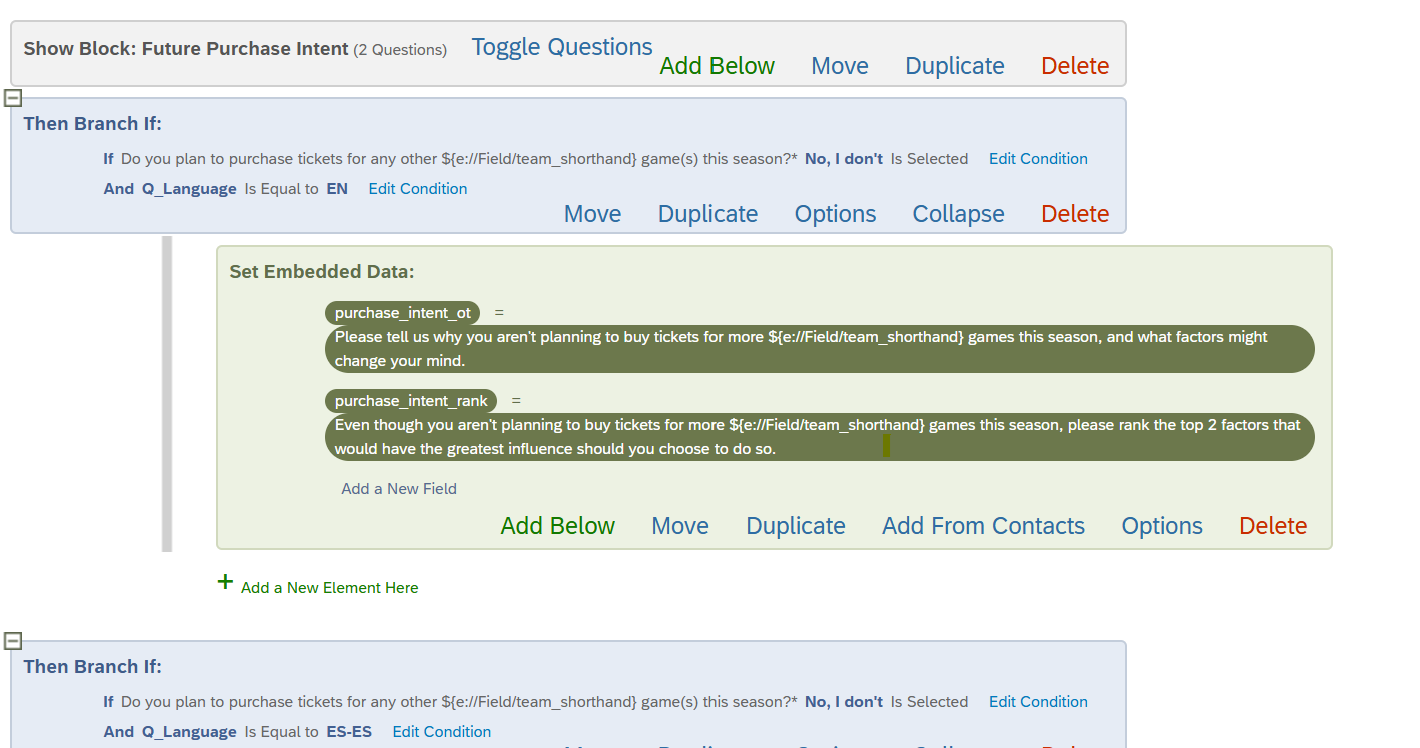
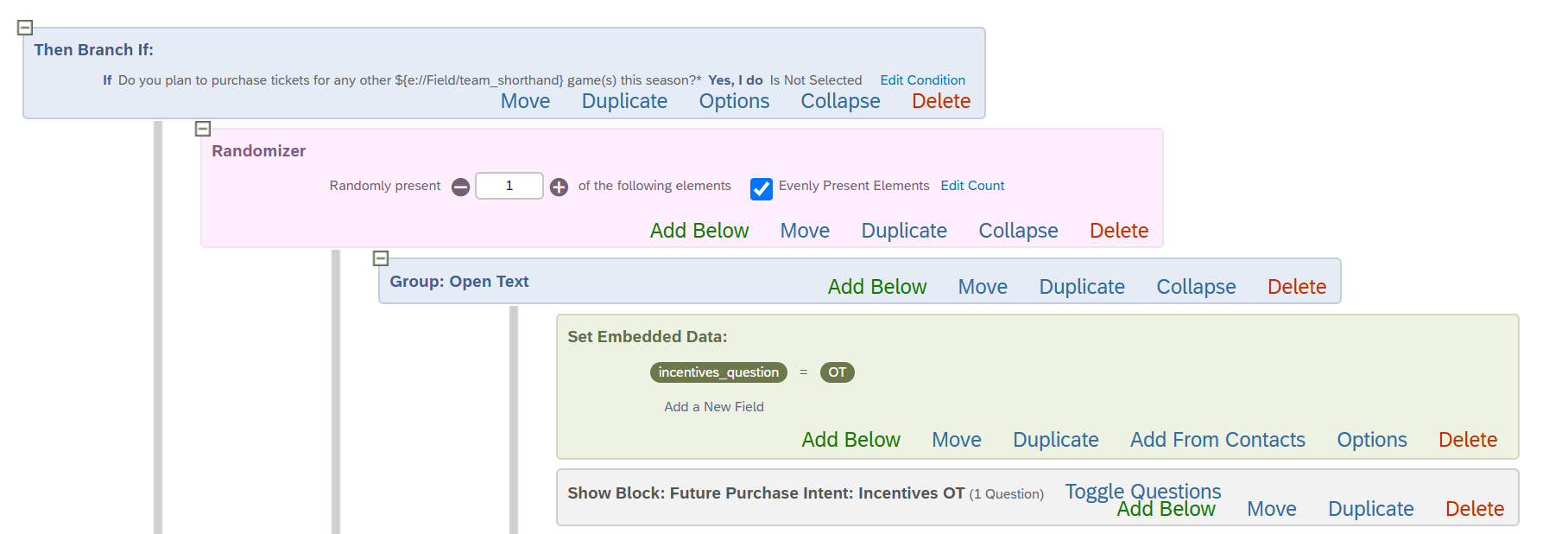
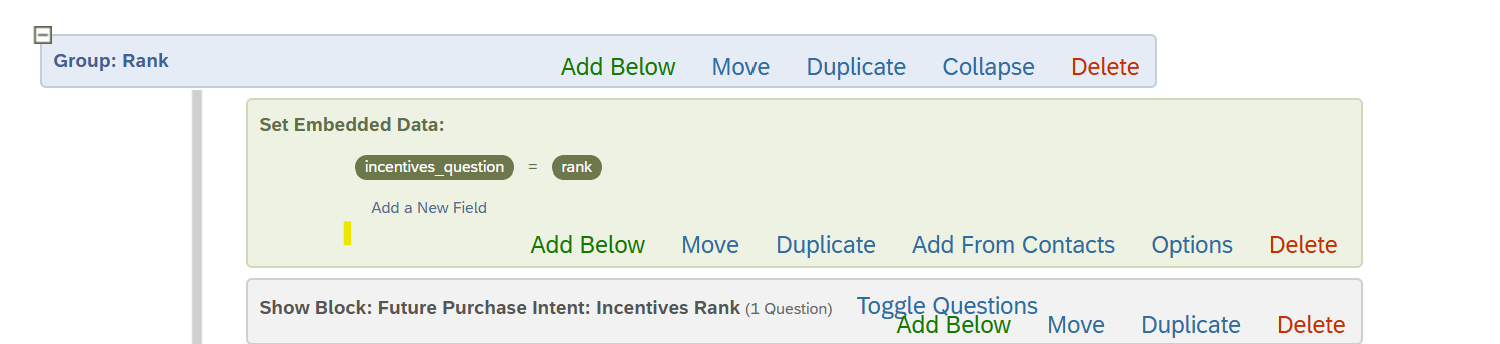
Our survey can be taken in English or Spanish, so we have an embedded data field (Q_Language) capturing this information at the start of the survey. While we have used the Qualtrics translations feature for the majority of our translations, there are two questions in the survey where we want to adjust our question text based on the respondent’s answer at a previous question. We have assigned question text via embedded data fields depending on if the respondent selected “No, I don’t” or “I’m not sure” at a previous question and also if they’re taking the survey in English or Spanish. From there, the respondent is randomly assigned to an open text or ranking question, utilizing the embedded data fields they were assigned in the question text.
While this appears to work correctly in our testing, we have seen a large number of situations in which the question text appears blank, leading us to believe that our branching or embedded data fields are not set up correctly. Could this be due to the order of our branching logic and when the respondent’s language is recorded (note this block is towards the end of the survey)? Also, any ideas as to why this is working the most of the time but not always would be much appreciated as we want to replicate this issue so we can be 100% sure that this is resolved once we find a solution.