Dear Qualtrics community,
I’m designing an experiment in Qualtrics. The set-up is quite straightforward, so that’s all fine. The only thing that I’m struggling with is the (pseudo)randomization of my questions. I couldn’t find a solution on the forum, so I was hoping someone can help me with this. The short question is: is there a way to tell Qualtrics to remember which question(s) it has already chosen from a Loop & merge list in previous blocks? Below is a more detailed explanation of the experiment and my question.
The general set-up of the experiment looks as follows: participants hear and see sentence-picture pairs (question). First they listen to a sentence, go to the next page and indicate whether this sentence matches a picture. Then they go to another page and describe a second picture. The combination of sentences and pictures is fixed. This part is no problem.
There are different sentence-picture pairs: (1) experimental sentence-picture pairs; and (2) control sentence-picture pairs. Here things become tricky. I want the control sentence-picture pairs to have a fixed location in the experiment. So, for example, trial 1 should be control sentence-picture pair 1; trial 3 should be control sentence-picture pair 2, etc. The experimental sentence-picture pairs should also have a fixed position in the experiment (for example, trial 2 and 4 should be experimental sentence-picture pairs). However, which exact experimental sentence-picture pair should appear in the designated position should be random. (It is actually more complicated than this, because I have different types of experimental sentence-picture pairs and there are some constraints on their order, but I think for now, this is less of a problem).
So the structure of the experiment would look something like this:
[1. Control sentence-picture pair - item 1]
[2. Experimental sentence-picture pair – random item]
[3. Control sentence-picture pair – item 2]
[4. Experimental sentence-picture pair – random item]
(Note that each item actually consists of 3 questions in Qualtrics.)
I thought I could very easily create this structure by creating separate blocks for the individual control sentence-picture pairs and by creating one block for the experimental sentence-picture pair items. I linked the ‘experimental’ block to a Loop & merge list with all the experimental sentence-picture pairs. I’ve told Qualtrics to only select one sentence-picture pair from the list at random. In the survey flow, I’ve duplicated the experimental block and placed it in the locations where the experimental sentence-picture pairs should appear (in between the control sentence-picture pairs). The good thing is that I can further specify this design by creating separate experimental blocks for my different types of experimental sentence-picture pairs. In principle, this design works, except that Qualtrics doesn’t remember which sentence-picture pairs it has already chosen from the Loop & merge list every time it starts again with the duplicated block. I don't want Qualtrics to re-use sentence-picture pairs it already presented, though.
Is there a way to make this design work? I’ve tried different designs as well, for example with separate blocks or questions for each experimental item. However, this did not work either (for example, 1 block with fixed control and randomized experimental sentence-picture pairs didn’t work, because it removed the page breaks, sentence-picture pairs consist of 3 different questions that should stay paired, and because I want to put constraints on randomization depending on the type of experimental sentence-picture pair). Unfortunately I don’t have experience with Javascript. I would very much appreciate any input, thanks!

Randomize Loop & merge table without redrawing between blocks
 +1
+1

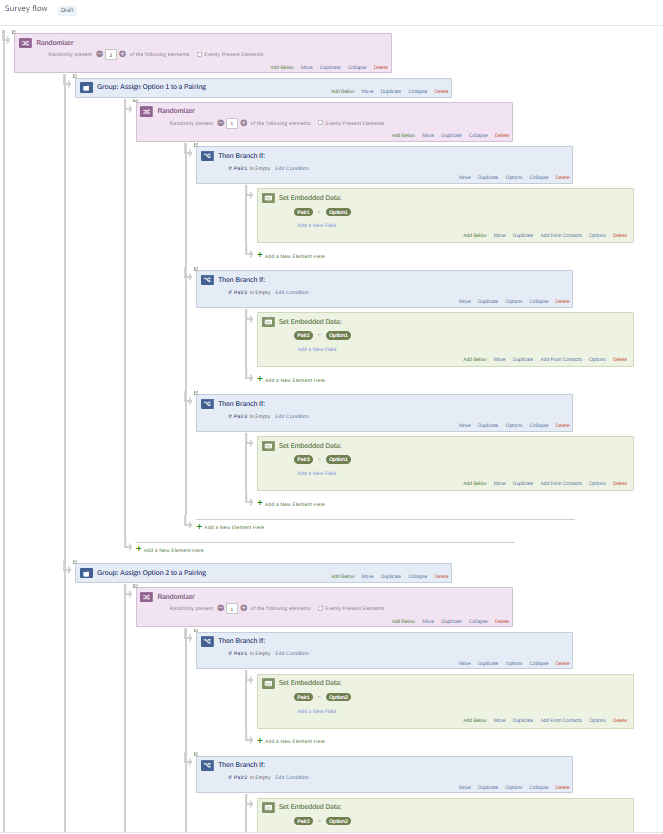 I just LABELED them as Option1, Option2, Option3, but you could use more meaningful content you actually intend to pipe in, etc, as needed.
I just LABELED them as Option1, Option2, Option3, but you could use more meaningful content you actually intend to pipe in, etc, as needed.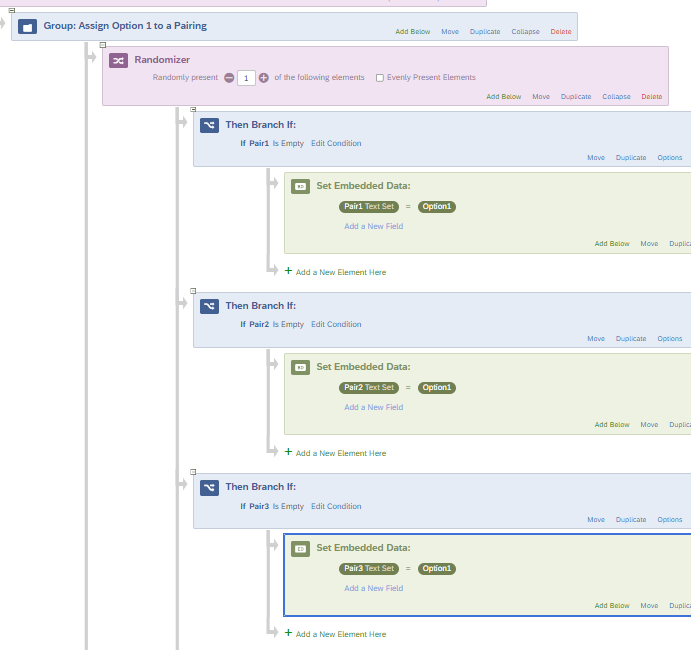 Basically, what it is doing is taking Option 1 and then I used a randomizer to assign that to one of the Pairings IF THAT PAIRING IS EMPTY.
Basically, what it is doing is taking Option 1 and then I used a randomizer to assign that to one of the Pairings IF THAT PAIRING IS EMPTY.Sign up
Already have an account? Login

Welcome! To join the Qualtrics Experience Community, log in with your existing Qualtrics credentials below.
Confirm your username, share a bit about yourself, then you're ready to explore and connect .
Free trial account? No problem. Log in with your trial credentials to join.
No free trial account? No problem! Register here
Already a member? Hi and welcome back! We're glad you're here 🙂
You will see the Qualtrics login page briefly before being taken to the Experience Community.
Login with Qualtrics
Welcome! To join the Qualtrics Experience Community, log in with your existing Qualtrics credentials below.
Confirm your username, share a bit about yourself, then you're ready to explore and connect .
Free trial account? No problem. Log in with your trial credentials to join. No free trial account? No problem! Register here
Already a member? Hi and welcome back! We're glad you're here 🙂
You will see the Qualtrics login page briefly before being taken to the Experience Community.
Login to the Community
No account yet? Create an account
Welcome! To join the Qualtrics Experience Community, log in with your existing Qualtrics credentials below.
Confirm your username, share a bit about yourself, then you're ready to explore and connect .
Free trial account? No problem. Log in with your trial credentials to join.
No free trial account? No problem! Register here
Already a member? Hi and welcome back! We're glad you're here 🙂
You will see the Qualtrics login page briefly before being taken to the Experience Community.
Login with Qualtrics
Welcome! To join the Qualtrics Experience Community, log in with your existing Qualtrics credentials below.
Confirm your username, share a bit about yourself, then you're ready to explore and connect .
Free trial account? No problem. Log in with your trial credentials to join. No free trial account? No problem! Register here
Already a member? Hi and welcome back! We're glad you're here 🙂
You will see the Qualtrics login page briefly before being taken to the Experience Community.
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.