
Hi all!
I have a within-subjects design that's already relying on some pretty complicated randomization and branch logic using embedded data to ensure the non-repeating random presentation of 4 condition blocks and 4 distractor tasks (one between each block) for each participant.
My problem is that I also want to randomize the insertion of 4 verbs, 1 verb per block, such that each condition is paired randomly with a verb, but no verb repeats across the 4 conditions. Again, this is within-subjects, so each participant is seeing all 4 conditions. Ideally, however the verbs and conditions are paired, I would be able to analyze the data after-the-fact and control for the verb selection in a regression model (in other words, I need to track the assignment).
There's a chance this problem could be solved without JS (I'm a complete newbie on the JS front)

Adding non-repeating piped data elements into questions text for within-subjects design
Best answer by CarolK
If you're already using blocks, I would consider this approach: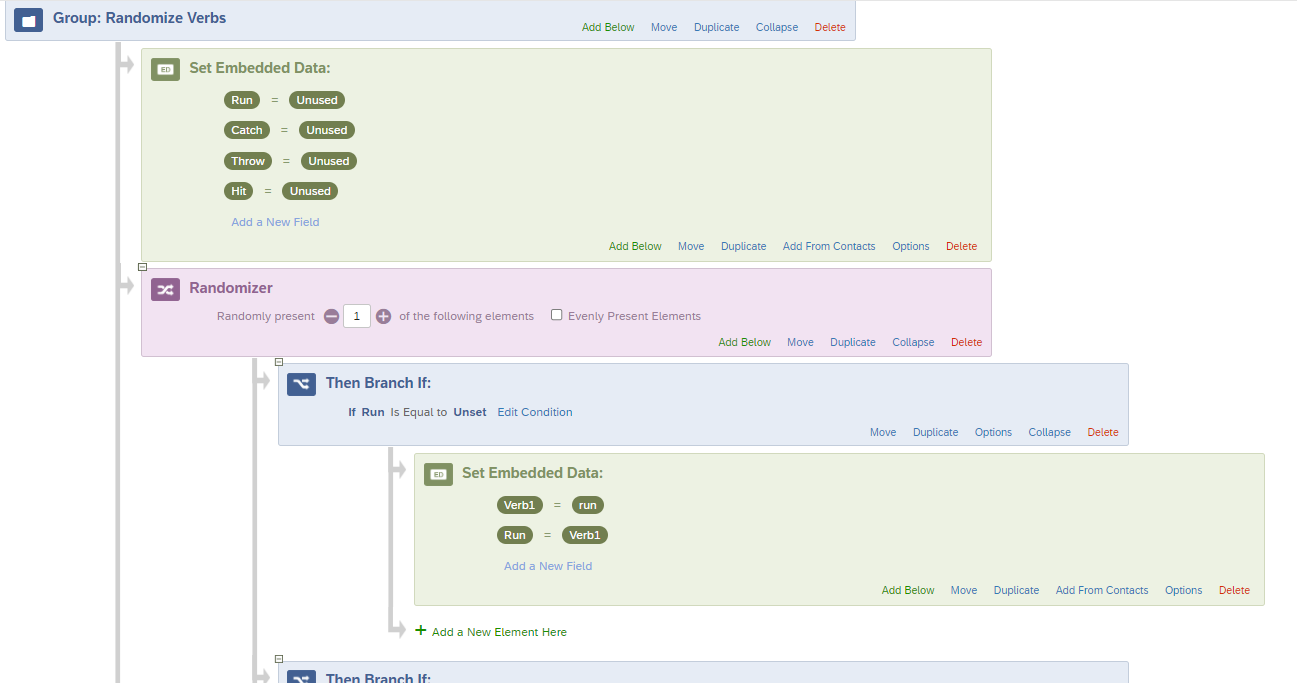 (I tend to put large chunks of survey flow content into a group so it's easy to collapse and navigate, that is just stylistic but it helps me. Since you mentioned your survey flow is already leveraging robust flow elements, it might help you too.)
(I tend to put large chunks of survey flow content into a group so it's easy to collapse and navigate, that is just stylistic but it helps me. Since you mentioned your survey flow is already leveraging robust flow elements, it might help you too.)
In the example above, I am assuming 4 verbs: Run, Catch, Throw, Hit (sorry, I just defaulted to baseball, just as an example)
To start, I set all of them to Unused. (Again, stylistic. Could have just used logic for "is empty" later, but this way all the verb selections are defined in the flow so I can pick them off the list as needed.)
Then the first randomizer (for Verb1) selects one of the verbs, sets the Verb1 values to whatever verb is selected (in whatever case you'll use it in the survey when you pipe it in), and changes the value of the verb so that it's no longer Unused.
I would then copy that entire randomizer and change all the Verb1 references to Verb2 (and so on for all 4 verbs). Because of the logic within the randomizer, no verb gets used twice. You could technically just do 3 randomizers, because after that whichever one has not been used can be set as Verb4 by default (assuming there ARE only 4 verbs available).

Sign up
Already have an account? Login

Welcome! To join the Qualtrics Experience Community, log in with your existing Qualtrics credentials below.
Confirm your username, share a bit about yourself, then you're ready to explore and connect .
Free trial account? No problem. Log in with your trial credentials to join.
No free trial account? No problem! Register here
Already a member? Hi and welcome back! We're glad you're here 🙂
You will see the Qualtrics login page briefly before being taken to the Experience Community.
Login with Qualtrics
Welcome! To join the Qualtrics Experience Community, log in with your existing Qualtrics credentials below.
Confirm your username, share a bit about yourself, then you're ready to explore and connect .
Free trial account? No problem. Log in with your trial credentials to join. No free trial account? No problem! Register here
Already a member? Hi and welcome back! We're glad you're here 🙂
You will see the Qualtrics login page briefly before being taken to the Experience Community.
Login to the Community
No account yet? Create an account
Welcome! To join the Qualtrics Experience Community, log in with your existing Qualtrics credentials below.
Confirm your username, share a bit about yourself, then you're ready to explore and connect .
Free trial account? No problem. Log in with your trial credentials to join.
No free trial account? No problem! Register here
Already a member? Hi and welcome back! We're glad you're here 🙂
You will see the Qualtrics login page briefly before being taken to the Experience Community.
Login with Qualtrics
Welcome! To join the Qualtrics Experience Community, log in with your existing Qualtrics credentials below.
Confirm your username, share a bit about yourself, then you're ready to explore and connect .
Free trial account? No problem. Log in with your trial credentials to join. No free trial account? No problem! Register here
Already a member? Hi and welcome back! We're glad you're here 🙂
You will see the Qualtrics login page briefly before being taken to the Experience Community.
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.