Dear community,
We are running a survey that randomly assigns respondents to receive a vignette about one of five technologies, and then answer questions related to that technology. The questions are the same across technologies, it is just the referent that is different (e.g. I can rely on Technology A/B/C/D/E). Obviously, these are housed within five different blocks, and those blocks are presented randomly.
When I download test data into SPSS, each referent variable has a column (e.g. Trust_A, Trust_B, Trust_C, Trust_D, Trust_E), and there are gaps depending on which condition a respondent answered - so if they answered questions relating to A, all of the other variables related to B-E are empty. What I want to do is have all responses under a merged "Trust" variable, and use a separate condition variable to test for differences (apologies for not explaining this very well!). Is there a way to set this up in Qualtrics so everything is pretty much arranged as I want when it comes to downloading the data, or is it a case of manipulating the data in SPSS post download?
Many thanks in advance
Kind regards
Steve

Asking the same questions about different referents across blocks - possible to merge responses?
 +1
+1Best answer by CarolK
If a person can only have answered one of these, then maybe what you want to do is go into the Data & Analysis tab, select Field Editor, and create a Combine field that Coalesces the value of all the values until it reaches one.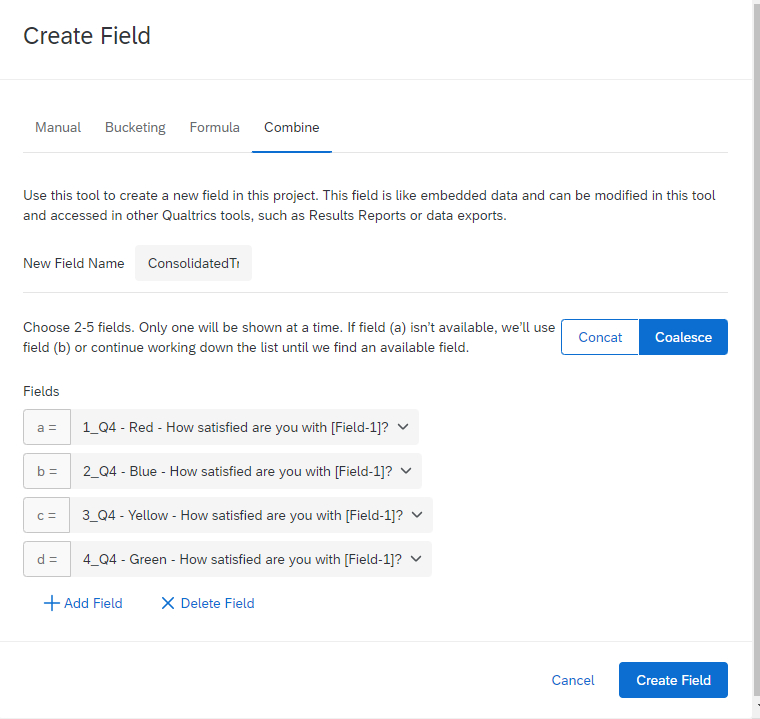 That is how to technically do it, but I will just say that not all SPSS programs treat embedded and custom variables the same way. Ours insists they are all text, not variables, so... Your Mileage May Vary. But I wish you luck!
That is how to technically do it, but I will just say that not all SPSS programs treat embedded and custom variables the same way. Ours insists they are all text, not variables, so... Your Mileage May Vary. But I wish you luck!


Sign up
Already have an account? Login

Welcome! To join the Qualtrics Experience Community, log in with your existing Qualtrics credentials below.
Confirm your username, share a bit about yourself, then you're ready to explore and connect .
Free trial account? No problem. Log in with your trial credentials to join.
No free trial account? No problem! Register here
Already a member? Hi and welcome back! We're glad you're here 🙂
You will see the Qualtrics login page briefly before being taken to the Experience Community.
Login with Qualtrics
Welcome! To join the Qualtrics Experience Community, log in with your existing Qualtrics credentials below.
Confirm your username, share a bit about yourself, then you're ready to explore and connect .
Free trial account? No problem. Log in with your trial credentials to join. No free trial account? No problem! Register here
Already a member? Hi and welcome back! We're glad you're here 🙂
You will see the Qualtrics login page briefly before being taken to the Experience Community.
Login to the Community
No account yet? Create an account
Welcome! To join the Qualtrics Experience Community, log in with your existing Qualtrics credentials below.
Confirm your username, share a bit about yourself, then you're ready to explore and connect .
Free trial account? No problem. Log in with your trial credentials to join.
No free trial account? No problem! Register here
Already a member? Hi and welcome back! We're glad you're here 🙂
You will see the Qualtrics login page briefly before being taken to the Experience Community.
Login with Qualtrics
Welcome! To join the Qualtrics Experience Community, log in with your existing Qualtrics credentials below.
Confirm your username, share a bit about yourself, then you're ready to explore and connect .
Free trial account? No problem. Log in with your trial credentials to join. No free trial account? No problem! Register here
Already a member? Hi and welcome back! We're glad you're here 🙂
You will see the Qualtrics login page briefly before being taken to the Experience Community.
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.