Hi, my research team is trying to construct an experiment that aims the effectiveness of different interventions on participant’s ability to judge the truthfulness of news headlines.
We have 32 headlines in total (16 Real, 16 Fake). We want to display 8 Real and 8 Fake headlines randomly prior to the intervention stage and display the rest of the headlines after the intervention. Is it possible to do so?
We have attempted to put all 32 headlines in one block and use the advanced randomiser to ask it to present a random subset of 16; however, this does not allow us to have a balanced number of Real and Fake headlines, plus we failed to figure out how to exclude the headlines that were displayed in the post-intervention block. Another approach we tried was to put each headline in an individual block. This allowed us to have exactly 8 Real and 8 Fake headlines pre- and post- intervention; however, the question of how to exclude the displayed headlines still stands.
Would really like to get some help on solving this problem! Many thanks in advance :)

Randomisation and excluding those that had been presented when showing the block a second time
 +1
+1Best answer by omkarkewat
Hi

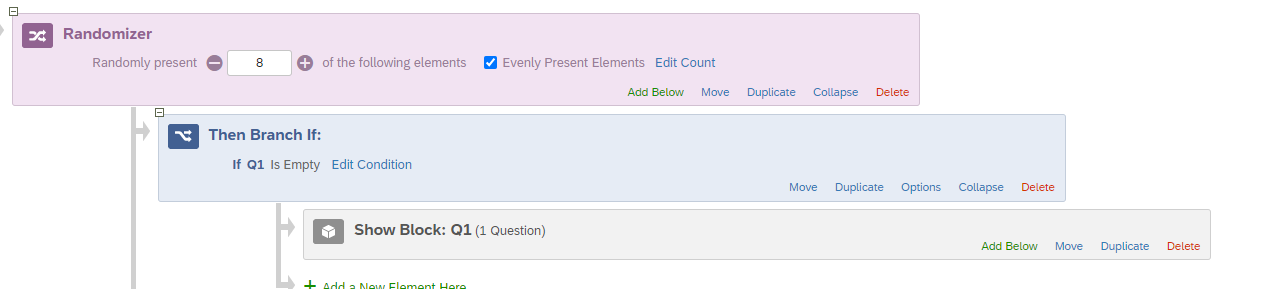
Let me know if it works!

Sign up
Already have an account? Login

Welcome! To join the Qualtrics Experience Community, log in with your existing Qualtrics credentials below.
Confirm your username, share a bit about yourself, then you're ready to explore and connect .
Free trial account? No problem. Log in with your trial credentials to join.
No free trial account? No problem! Register here
Already a member? Hi and welcome back! We're glad you're here 🙂
You will see the Qualtrics login page briefly before being taken to the Experience Community.
Login with Qualtrics
Welcome! To join the Qualtrics Experience Community, log in with your existing Qualtrics credentials below.
Confirm your username, share a bit about yourself, then you're ready to explore and connect .
Free trial account? No problem. Log in with your trial credentials to join. No free trial account? No problem! Register here
Already a member? Hi and welcome back! We're glad you're here 🙂
You will see the Qualtrics login page briefly before being taken to the Experience Community.
Login to the Community
No account yet? Create an account
Welcome! To join the Qualtrics Experience Community, log in with your existing Qualtrics credentials below.
Confirm your username, share a bit about yourself, then you're ready to explore and connect .
Free trial account? No problem. Log in with your trial credentials to join.
No free trial account? No problem! Register here
Already a member? Hi and welcome back! We're glad you're here 🙂
You will see the Qualtrics login page briefly before being taken to the Experience Community.
Login with Qualtrics
Welcome! To join the Qualtrics Experience Community, log in with your existing Qualtrics credentials below.
Confirm your username, share a bit about yourself, then you're ready to explore and connect .
Free trial account? No problem. Log in with your trial credentials to join. No free trial account? No problem! Register here
Already a member? Hi and welcome back! We're glad you're here 🙂
You will see the Qualtrics login page briefly before being taken to the Experience Community.
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.