
I recently had a project where I had to manually adjust over 100 variable names in a .csv file because of the way data for loop and merge are stored. After this manipulation I read the file into Stata and reshaped from wide to long so it could be used in Vocalize, but it seems important even for analyses in any program to do some sort of reshaping (or stacking). It seems to me that a simple fix would be to allow users to pick how data are stored when using loop and merge (e.g., whether they want the leading number to instead appear at the end). This would given everyone a much more efficient experience. I'll illustrate an example of the problem in greater detail below. Does anyone have work arounds or ideas? I also posted in the product idea section.
For the purposes of an example, let's say we have a multiselect item where students identify the schools they have attended from a list of four.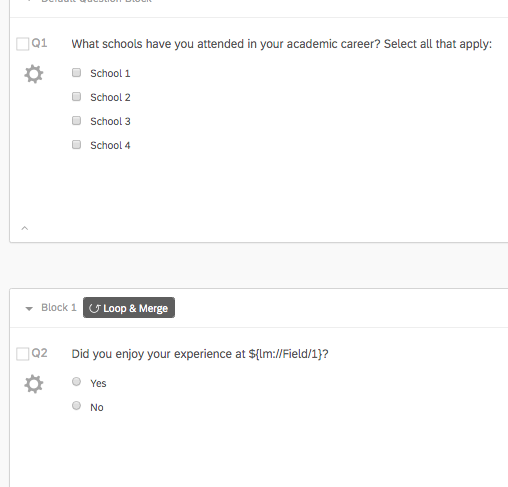
With the second item set up like this: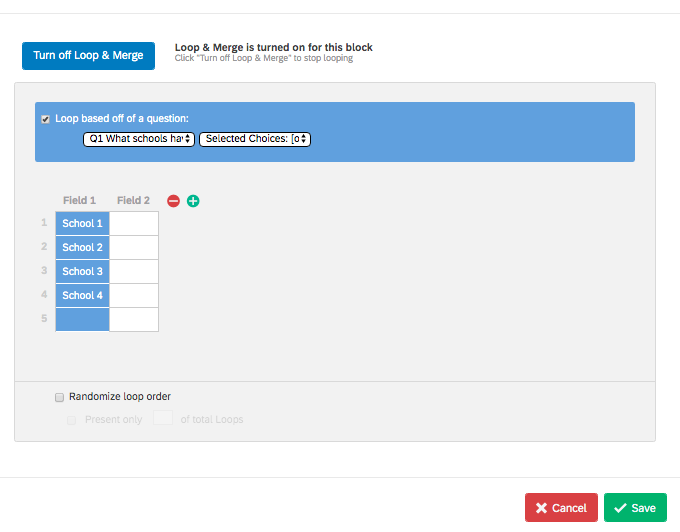
The way these data are stored is 1_[var], 2_[var], etc. at the front of the variable based on the position of the identifier in the loop. See below: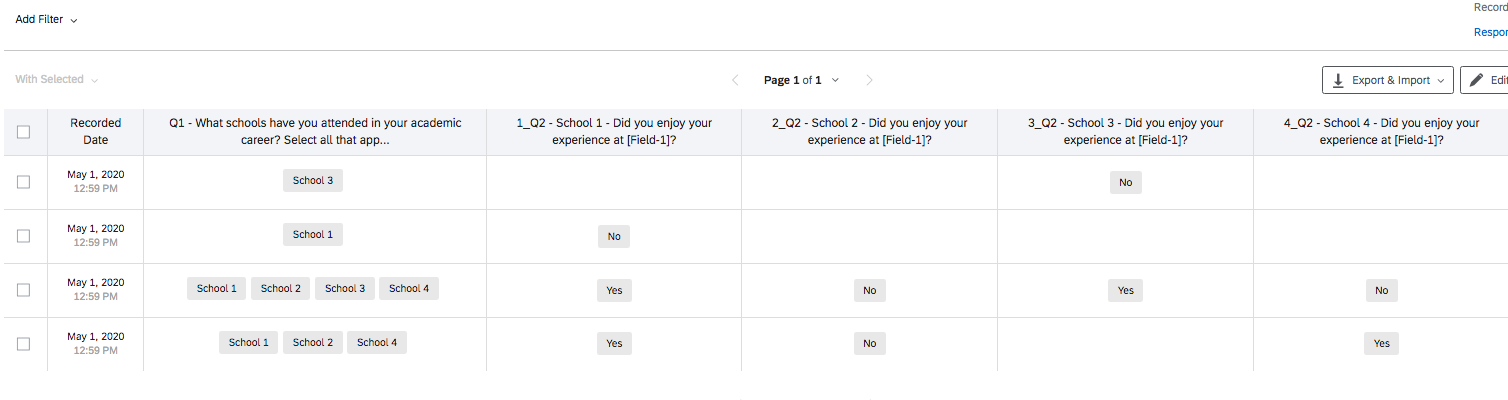
However, Stata, SPSS, and Python (and probably most, if not all, other data manipulation tools) will not read in variables with leading numbers. Moreover, for Stata at least, reshaping from wide to long works much better if the identifier appears at the end of the variable, like [var]1 for School 1 instead of 1_[var].
It's the same in the data file export:
Thus, as it stands, one has to manually adjust the variable names for each school-by_variable combination -- removing the "1_" and adding a "1" at the end and so on. So if you had, say, a survey of 50 items and 150 schools, that's 7,500 manual manipulations before one can even read these data into Stata.
I called technical support and they asked around and no one had a good solution. I think this would save everyone a lot of time if it were possible:
Solution: allow for users to choose where how they want the loop identifier denoted in the survey data.

loop & merge variable naming? Stata doesn't work with leading number denotation


Sign up
Already have an account? Login

Welcome! To join the Qualtrics Experience Community, log in with your existing Qualtrics credentials below.
Confirm your username, share a bit about yourself, then you're ready to explore and connect .
Free trial account? No problem. Log in with your trial credentials to join.
No free trial account? No problem! Register here
Already a member? Hi and welcome back! We're glad you're here 🙂
You will see the Qualtrics login page briefly before being taken to the Experience Community.
Login with Qualtrics
Welcome! To join the Qualtrics Experience Community, log in with your existing Qualtrics credentials below.
Confirm your username, share a bit about yourself, then you're ready to explore and connect .
Free trial account? No problem. Log in with your trial credentials to join. No free trial account? No problem! Register here
Already a member? Hi and welcome back! We're glad you're here 🙂
You will see the Qualtrics login page briefly before being taken to the Experience Community.
Login to the Community
No account yet? Create an account
Welcome! To join the Qualtrics Experience Community, log in with your existing Qualtrics credentials below.
Confirm your username, share a bit about yourself, then you're ready to explore and connect .
Free trial account? No problem. Log in with your trial credentials to join.
No free trial account? No problem! Register here
Already a member? Hi and welcome back! We're glad you're here 🙂
You will see the Qualtrics login page briefly before being taken to the Experience Community.
Login with Qualtrics
Welcome! To join the Qualtrics Experience Community, log in with your existing Qualtrics credentials below.
Confirm your username, share a bit about yourself, then you're ready to explore and connect .
Free trial account? No problem. Log in with your trial credentials to join. No free trial account? No problem! Register here
Already a member? Hi and welcome back! We're glad you're here 🙂
You will see the Qualtrics login page briefly before being taken to the Experience Community.
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.